
128K
0.364
0.546
Chat
Active
DeepSeek-V3.1-Terminus
Ideal for coding, web navigation, command-line automation, and other agentic workflows, it blends powerful model capacity with flexible inference modes.


DeepSeek V3.1 Terminus is a state-of-the-art large-scale hybrid reasoning AI model designed for complex tasks involving chain-of-thought reasoning.
DeepSeek V3.1 Terminus is a state-of-the-art large-scale hybrid reasoning AI model designed for complex tasks involving chain-of-thought reasoning. This update refines DeepSeek's V3 line, focusing on enhanced stability, improved agent/tool workflows, and reliable multi-step reasoning capabilities. Ideal for coding, web navigation, command-line automation, and other agentic workflows, it blends powerful model capacity with flexible inference modes.
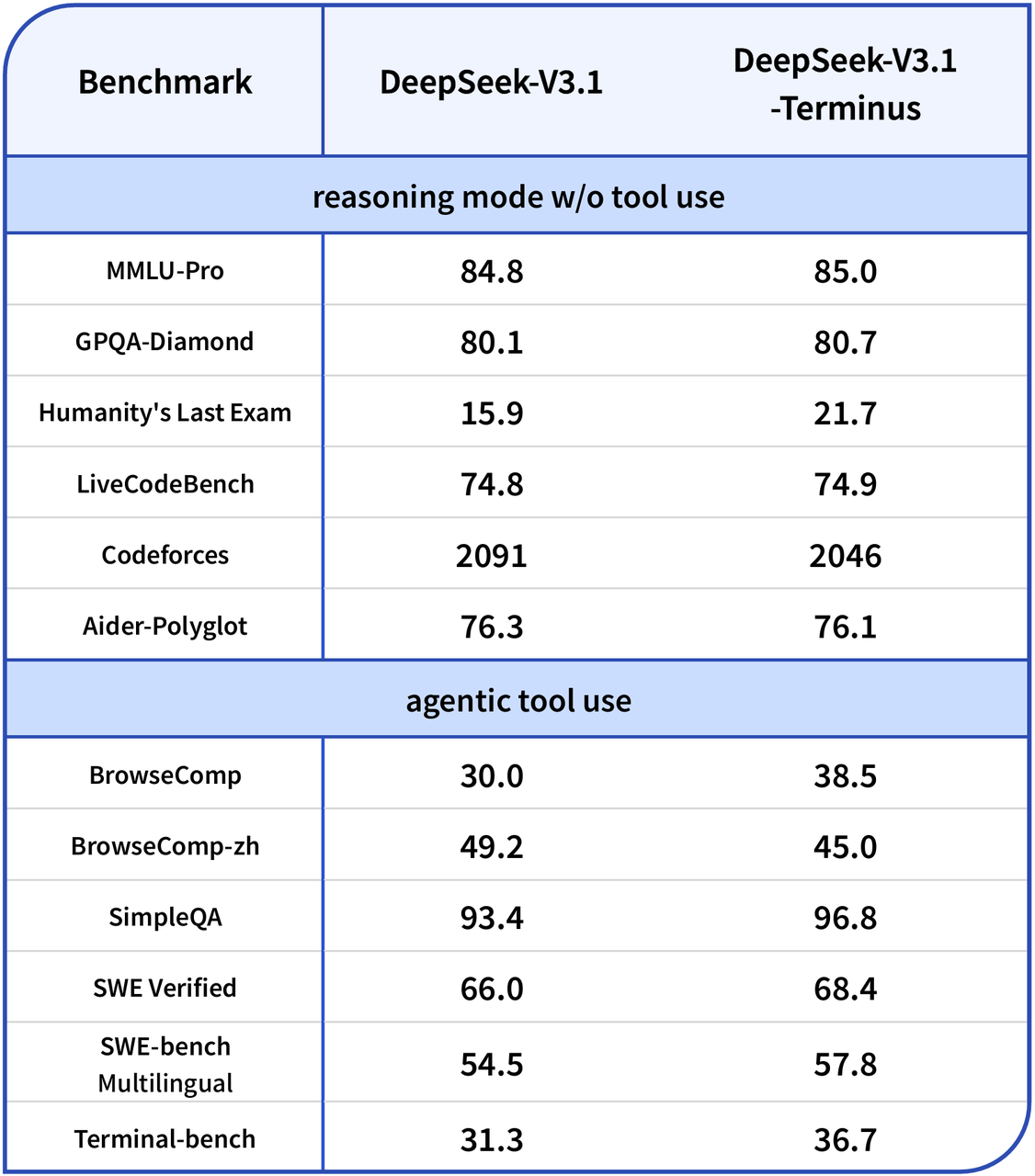
vs GPT-4: GPT-4 is well-known for versatility and creativity, strong in general reasoning and dialogue quality; DeepSeek Terminus excels in agentic workflows and multi-step tool invocation efficiency with lower token costs.
vs Claude 4.1: Claude 4.1 leads in intuitive, creative multi-step reasoning and excels in smooth chain-of-thought tasks; DeepSeek Terminus matches closely in complex agentic workflows where tool integration and explicit planning are critical.
Vs DeepSeek R1: Terminus achieves comparable reasoning quality with faster response times and lower output token consumption.
Vs DeepSeek V3.1: Terminus improves language stability, reduces character glitches, and boosts agent/tool coordination.
DeepSeek V3.1 Terminus is a state-of-the-art large-scale hybrid reasoning AI model designed for complex tasks involving chain-of-thought reasoning. This update refines DeepSeek's V3 line, focusing on enhanced stability, improved agent/tool workflows, and reliable multi-step reasoning capabilities. Ideal for coding, web navigation, command-line automation, and other agentic workflows, it blends powerful model capacity with flexible inference modes.
vs GPT-4: GPT-4 is well-known for versatility and creativity, strong in general reasoning and dialogue quality; DeepSeek Terminus excels in agentic workflows and multi-step tool invocation efficiency with lower token costs.
vs Claude 4.1: Claude 4.1 leads in intuitive, creative multi-step reasoning and excels in smooth chain-of-thought tasks; DeepSeek Terminus matches closely in complex agentic workflows where tool integration and explicit planning are critical.
Vs DeepSeek R1: Terminus achieves comparable reasoning quality with faster response times and lower output token consumption.
Vs DeepSeek V3.1: Terminus improves language stability, reduces character glitches, and boosts agent/tool coordination.





.webp)



