
Claude Fable 5: Anthropic's most capable publicly available model
What is Claude Fable 5?
Claude Fable 5 is Anthropic's most powerful publicly released AI model to date, launched on June 9, 2026. It belongs to the Mythos model class — a tier reserved for models with advanced reasoning, extended context handling, and the ability to autonomously work through complex, multi-step problems over long periods of time. Prior to Fable 5, Mythos-class models were only accessible through restricted programs. Fable 5 changes that.
In practical terms, Fable 5 is significantly better than Opus 4.8 across nearly every tested dimension: coding, knowledge work, vision, memory, and scientific research. It does not just answer harder questions, it sustains coherent, goal-directed behavior across millions of tokens, revisits its own outputs, and recovers gracefully from failures. For developers and researchers who have been waiting for a commercially viable frontier model that can actually operate as an autonomous agent, Fable 5 is the first release to genuinely deliver on that promise.
It is worth noting that Fable 5 and the restricted Mythos 5 share the same underlying model weights. The difference lies in the safety configuration, not in raw capability — a distinction that has significant implications for how each version can be used.
Fable 5 vs Mythos 5 — understanding the two variants
Anthropic launched two versions simultaneously. Understanding the difference is important for anyone evaluating whether Fable 5 meets their needs.
Fable 5's safety configuration is deliberately conservative. Anthropic acknowledges that the guardrails will occasionally intercept harmless requests — in particular, around topics like cybersecurity and biology where the model's capabilities are most powerful and most potentially misusable. The estimated trigger rate is less than 5% of sessions, and when a guardrail fires, the request is routed to Claude Opus 4.8 rather than returning an error. This is transparent and practical, though developers should be aware of it when building applications in adjacent domains.
Benchmark performance and capabilities
Fable 5 sets new state-of-the-art scores on nearly every major AI benchmark as of its release date. But benchmark numbers alone can be misleading, what is more meaningful is where Fable 5 actually outperforms its predecessors in ways that translate directly to real use.
- #1 CursorBench (coding)
- #1 Hebbia Finance Benchmark
- #1 FrontierCode eval (Cognition)
- <5% Guardrail trigger rate
- ~10× Drug design acceleration
- ~80% Preferred in sci. hypothesis review
Software engineering
Software engineering is where Fable 5 shows the most dramatic gains. In early access testing with Stripe, the model completed a codebase-wide migration across a 50-million-line Ruby repository in a single day; a task their team estimated would have taken more than two months working manually. This is not just a speed improvement; it represents a qualitative shift in how AI can be integrated into production engineering workflows.
On Cognition's FrontierCode benchmark, which evaluates whether models can pass difficult coding tasks while also meeting the standards of real production codebases, Fable 5 ranked highest among all frontier models, even at medium compute effort. Token efficiency is meaningfully better than previous Claude generations, which matters in long agentic runs where costs compound quickly.
Knowledge work and financial analysis
On Hebbia's Finance Benchmark, designed to simulate senior research analyst-level reasoning, Fable 5 achieved the highest score of any model tested. The gains were particularly noticeable in document-based reasoning, chart and table interpretation, and multi-step problem solving. IMC, the quantitative trading firm, reported that Fable 5 aced their trading-analysis evaluation suite across factual lookup, root-cause analysis, and expected-value computation.
Vision capabilities
Fable 5 is the new leading model for vision-based tasks. It can extract precise numerical data from dense scientific figures, reconstruct a web application's source code from nothing but a screenshot, and complete vision-only tasks that previously required extensive scaffolding. A clear benchmark of this: earlier Claude models needed a complex harness of helper tools to play Pokémon FireRed. Fable 5 beat the game using only raw screen images, with no maps, navigation aids, or external game-state information. For developers building vision-heavy workflows, this is a meaningful step forward.
Memory and long-context performance
One of Fable 5's distinguishing traits is how it handles very long runs. The model can stay on task across millions of tokens, and its performance actually improves when it is given access to persistent memory tools. In Anthropic's Slay the Spire evaluation (a deck-building game used as a proxy for complex long-horizon decision making), giving Fable 5 file-based memory improved its performance three times more than the equivalent setup improved Opus 4.8's performance. Fable also reached the game's final act three times more frequently. For developers running extended agent workflows, this is a meaningful and practically relevant advantage.
Real-world applications
The most compelling evidence for Fable 5's capabilities comes from the domains where Anthropic's internal teams and early-access partners have actually put it to work. These are not toy benchmarks, they are production-level research problems and engineering challenges.
Agentic software development
Complete multi-month engineering projects autonomously — refactors, migrations, architecture changes — across massive codebases.
Financial and investment analysis
Senior-grade reasoning over complex financial documents, charts, tables, and multi-step expected-value problems.
Drug discovery and protein design
Autonomous protein target selection, tool operation, and failure recovery — accelerating drug design workflows by roughly 10×.
Genomics research
Mythos 5 conducted over a week of autonomous genomics research, training a custom ML model that outperformed a recently published Science paper.
Vision-driven automation
Reconstruct interfaces, extract data from scientific charts, and control software using screen images alone — no specialized scaffolding required.
Legal document review
In blind review tests, legal professionals found Fable 5's contract redlines matched or exceeded their existing model on every comparison.
Scientific hypothesis generation
Perhaps the most striking result from Anthropic's internal testing is in molecular biology. Mythos 5 is described as the first Claude model to consistently generate novel, compelling scientific hypotheses. In blind head-to-head comparisons against Opus-class models, Anthropic's scientists preferred Mythos 5's hypotheses roughly 80% of the time. Several have already been advanced to experimental evaluation. One hypothesis about a novel mechanism in an E. coli protein was independently corroborated by a separate lab's published research, suggesting the model's scientific reasoning is tracking something real, not just pattern-matching on existing literature.
Safety and guardrails — a practical explanation
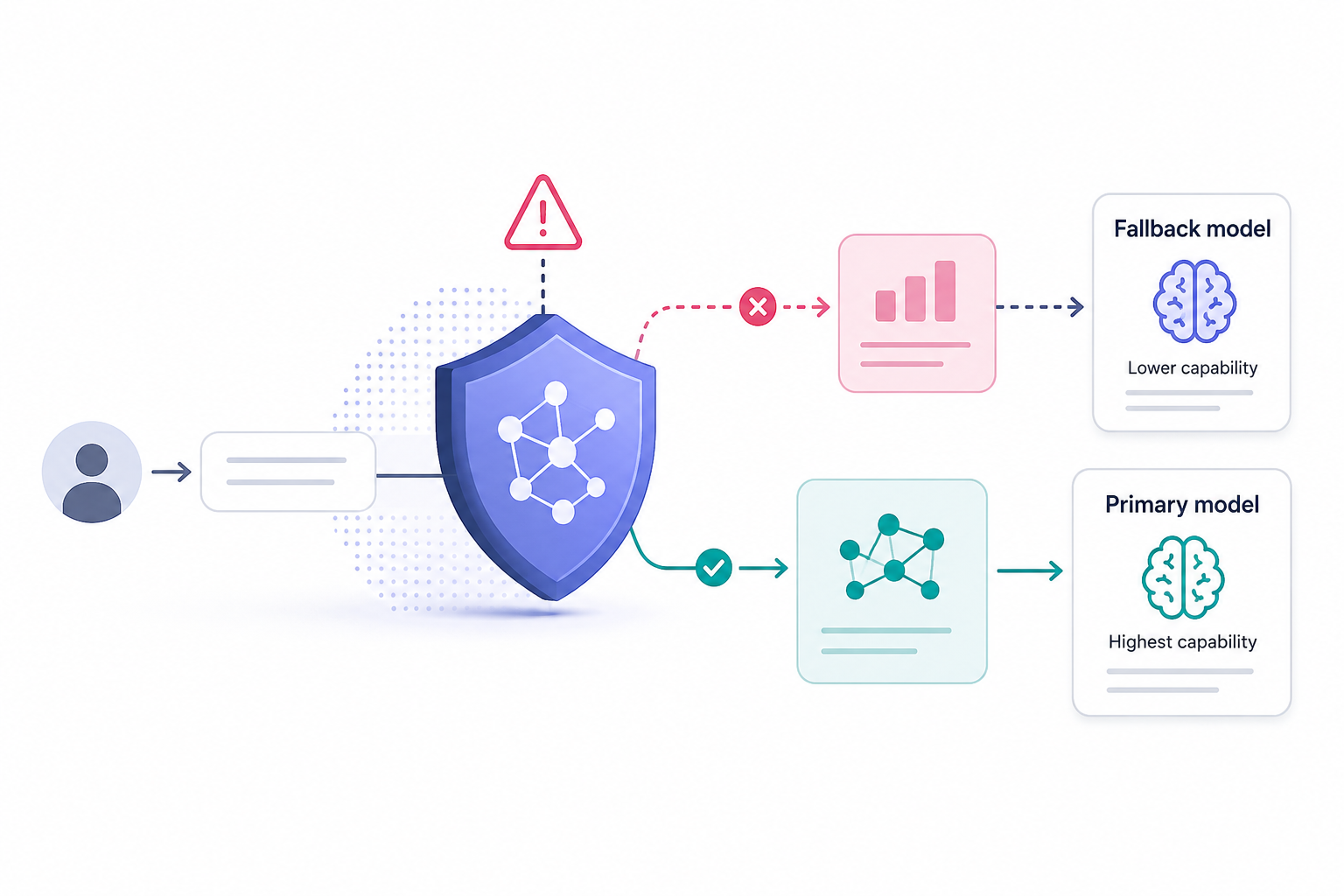
Releasing a Mythos-class model publicly comes with genuine risks. Fable 5's capabilities in cybersecurity, biology, and other sensitive domains are strong enough to cause real damage if misused. Anthropic's approach has been to add a safety layer that intercepts high-risk queries and routes them to Opus 4.8 instead.
This means Fable 5 users will occasionally find that a query, even a legitimate one, triggers the guardrail and receives a lower-capability response. Anthropic acknowledges this directly, noting that the thresholds have been set conservatively on purpose. The company frames this as a deliberate trade-off: deploy the model quickly, accept some false positives, and refine the system over time as more capable safety tooling becomes available. The trigger rate across all sessions is estimated at under 5%, so most use cases will not be affected.
On alignment specifically, Anthropic's automated assessment found Mythos 5 (and therefore Fable 5, which shares the same base model) showed low levels of misaligned behavior, including deception and cooperation with misuse, comparable to Opus 4.8.
Access Claude Fable 5 through the API today
AI/ML API offers seamless access to Claude Fable 5 and 500+ other frontier models through a single unified API — with pay-as-you-go pricing, multi-model routing, and no infrastructure overhead.
Frequently asked questions
How is Fable 5 different from previous Claude models like Opus 4.8?
Opus 4.8 was the previous frontier model in Anthropic's public lineup. Fable 5 exceeds it in nearly every area that matters for demanding use cases. The performance gap is most pronounced on long-horizon tasks: the longer and more complex the job, the bigger Fable 5's lead tends to be.
What is the difference between Claude Fable 5 and Claude Mythos 5?
Fable 5 and Mythos 5 share the same underlying model — the same weights, the same architecture, the same raw capability. The difference is entirely in safety configuration. Fable 5 ships with conservative safety guardrails that intercept high-risk queries (particularly in cybersecurity and biology) and route them to Opus 4.8 instead.
Mythos 5 has those guardrails lifted in specific areas and is only available to a small group of trusted partners — cyberdefenders, infrastructure providers, and US government collaborators — through Anthropic's Project Glasswing program. For general developers and enterprises, Fable 5 is the version to use.
What is Fable 5 best at compared to other frontier models?
Fable 5 leads on benchmarks that require sustained, multi-step reasoning and execution — particularly in software engineering, financial analysis, and scientific research. On Cognition's FrontierCode benchmark, Fable 5 ranks highest among all frontier models. On Hebbia's Finance Benchmark for senior-analyst-level reasoning, it also scores highest. For tasks involving vision, it is the current state-of-the-art model.
How good is Fable 5 at coding and software engineering?
It is the strongest publicly available model for coding as of its release. In real-world testing, Stripe reported that Fable 5 performed a full codebase migration across a 50-million-line Ruby repository in a single day — a task their engineers estimated would take a full team over two months by hand. It is not just fast: it is also more token-efficient than prior Claude models, meaning it can do more work before context limits become an issue.



