
GLM 5.2: Zhipu AI's Most Capable Model Yet
What's new
Five major upgrades over previous GLM generations
Rather than chasing a single benchmark, GLM 5.2 was designed as a comprehensive upgrade across the areas that matter most for real production deployments: multi-step reasoning, code generation, agentic task completion, context length, and operating efficiency.
Advanced reasoning
Stronger multi-step problem solving, logical consistency, and instruction following — especially in mathematical, scientific, and business workflow contexts.
- Math
- Science
- Planning
Coding performance
Higher-quality completions with fewer hallucinations across Python, JavaScript, TypeScript, C++, Java, and SQL. Better repository-level understanding built in.
- Python
- JS/TS
- SQL
- Debugging
AI agent workflows
Optimized for function calling, tool use, browser automation, and multi-step API orchestration — the architecture of AI that actually does things.
- Tool use
- Planning
- Memory
Long context window
Process full documents, large codebases, legal contracts, and enterprise knowledge bases. Designed for RAG pipelines and multi-document synthesis.
- RAG
- Legal
- Codebases
Enterprise optimization
Lower inference costs, faster latency, scalable APIs, and support for private on-premise deployments — benchmarks matter, but so does cost per token at scale.
- Low latency
- Private deploy
How GLM 5.2 fits the landscape
Competing at the frontier level
The 2026 LLM market is more competitive than at any point in AI history. GLM 5.2 enters with a clear strategy: balance reasoning depth, coding ability, and multilingual strength against the most established players, while offering better cost efficiency for enterprise scale.
Built for AI that completes tasks, not just answers questions
The defining shift in AI applications in 2026 is the move from conversational assistants to autonomous systems that can reason across steps, interact with external tools, and maintain context through long workflows. GLM 5.2 is specifically designed for this paradigm.
Receive a high-level task
A user or orchestration system hands off a complex goal — write a codebase, analyze a 200-page contract, or research and summarize a technical topic.
Break it into steps and call tools
GLM 5.2 plans a sequence of sub-tasks, using function calling and tool APIs to take real actions — searches, code executions, file reads, API calls.
Maintain context across the workflow
Using the expanded context window, GLM 5.2 holds the full state of a long workflow without losing track of earlier steps or intermediate results.
Deliver a structured, accurate output
The agent produces a final result that reflects multi-step reasoning — not a hallucinated shortcut but an honest synthesis of everything it discovered and built along the way.
Four audiences who benefit most
GLM 5.2 isn't trying to be everything to everyone — but its combination of general-purpose strength and specialized enterprise focus makes it genuinely useful across several distinct user groups.
- AI developers: Production system builders who need reliable tool use, function calling, and coding accuracy. GLM 5.2 reduces the friction of integrating AI into real applications.
- Enterprise teams: Organizations running internal knowledge systems, workflow automation, or document analysis at scale. The model's cost efficiency and private deployment options are key.
- Researchers: Academics and technical researchers who need multilingual document handling, long-context reasoning, and reliable synthesis across large corpora.
- Startups: Teams looking for frontier-level performance without premium pricing — GLM 5.2's efficiency focus makes it an attractive alternative for cost-sensitive early-stage products.
Why GLM 5.2 matters beyond the benchmarks
Two years ago, the frontier AI conversation was dominated almost entirely by American laboratories. Today, Zhipu AI, Alibaba, Moonshot AI, DeepSeek, and Tencent are producing models that are genuinely competitive across reasoning, coding, multimodal understanding, and agentic capabilities.
This isn't just a geopolitical observation — it's a practical one for developers and enterprises. A more global AI ecosystem means more competition, which accelerates innovation, reduces costs, and gives builders more real choices than they've ever had. GLM 5.2 is a direct expression of this shift, and regardless of where it lands in independent benchmarks, the release raises the bar for everyone.
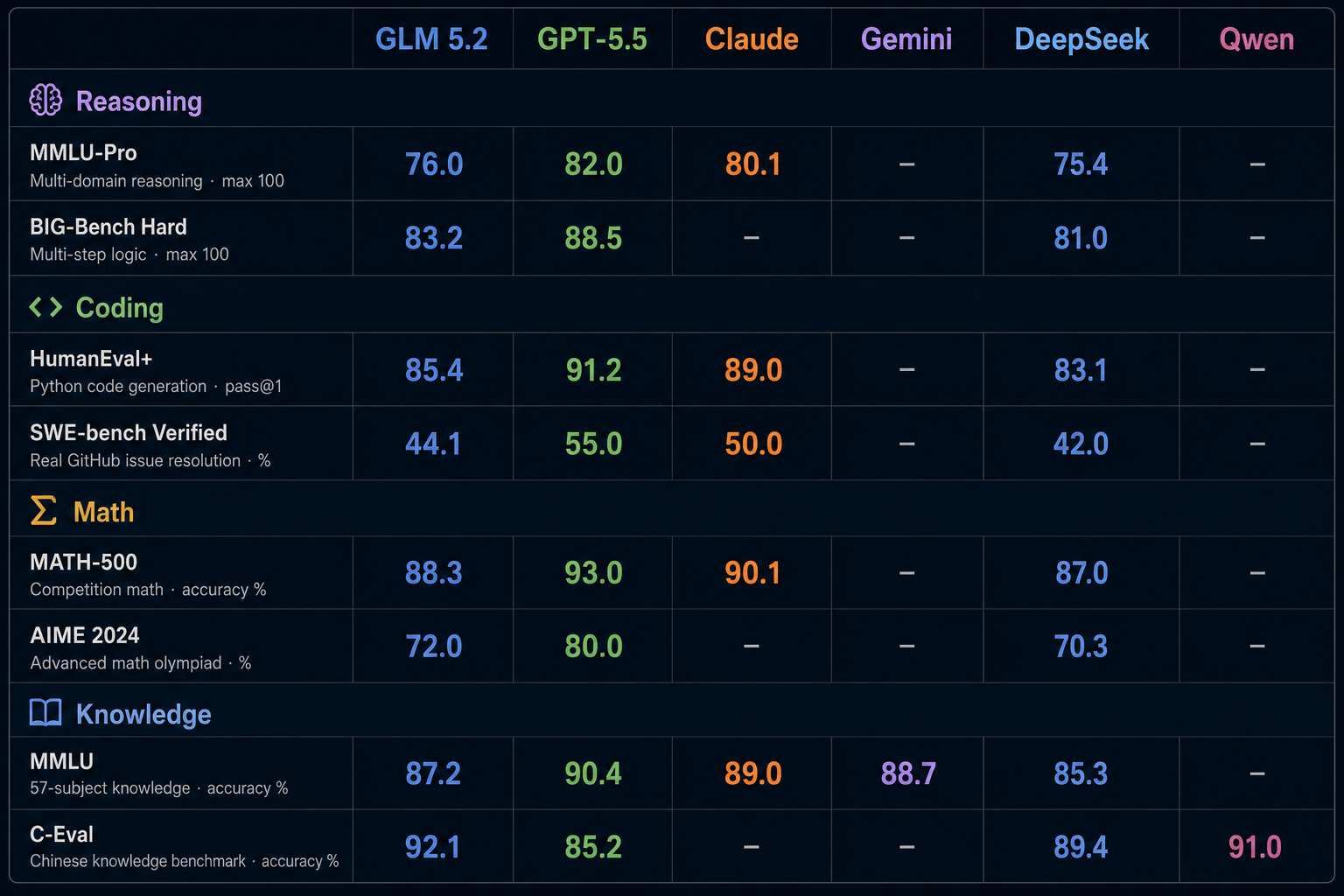
How GLM 5.2 performs on key benchmarks
Benchmark scores offer an imperfect but useful signal. Below are representative results across reasoning, coding, math, and knowledge tasks, placing GLM 5.2 alongside its closest competitors. Scores reflect reported or estimated figures at time of release and should be treated as directional, not definitive.
Start building with GLM 5.2 today
Access GLM 5.2 and 500+ other frontier models through a single, unified API.
Frequently asked questions
What is GLM 5.2 and who made it? GLM 5.2 is a large language model developed by Zhipu AI, a leading AI research laboratory based in Beijing. It is the latest generation of the GLM (General Language Model) series, designed for reasoning, coding, agentic tasks, and enterprise deployment. Zhipu AI was founded in 2019 and has grown into one of China's most prominent foundation model developers.
How does GLM 5.2 differ from GLM 4 and earlier versions? GLM 5.2 represents a substantial leap from GLM 4 across five core areas: multi-step reasoning, coding accuracy, autonomous agent capabilities, context window length, and inference efficiency. Earlier GLM versions were primarily optimized for conversational tasks and general knowledge. GLM 5.2 shifts focus toward production AI systems that can plan, use tools, and complete complex tasks autonomously.
How long is GLM 5.2's context window? GLM 5.2 supports a significantly expanded context window compared to its predecessors, designed to handle full documents, large codebases, legal contracts, and enterprise knowledge bases in a single pass. The model's long-context capability is particularly useful for retrieval-augmented generation (RAG), multi-document summarization, and code repository analysis. Specific token limits are confirmed through the official API documentation.
How does GLM 5.2 compare to DeepSeek and Qwen? All three are competitive Chinese frontier models with different design emphases. DeepSeek is known for strong open-source efficiency and mathematical reasoning. Qwen (Alibaba) excels in multilingual tasks and has a broad model family from small to very large. GLM 5.2 distinguishes itself through its enterprise deployment focus, agent workflow optimization, and Zhipu AI's investment in long-context processing. In practice, the right model depends on your specific task — try all three on your real workload before committing.



