
200K
6.5
32.5
Chat
Active
Claude Opus 4.5
It excels in software engineering and agentic workflows, supports advanced tool use and large context windowsl.


Claude 4.5 Opus is a breakthrough AI model offering unmatched intelligence, multi-step reasoning, and efficiency.
Claude 4.5 Opus sets a new standard in AI performance, focusing on intelligence, efficiency, and practical utility. This model excels in complex tasks like coding, agentic operations, and deep research, while prioritizing robust safety and alignment.
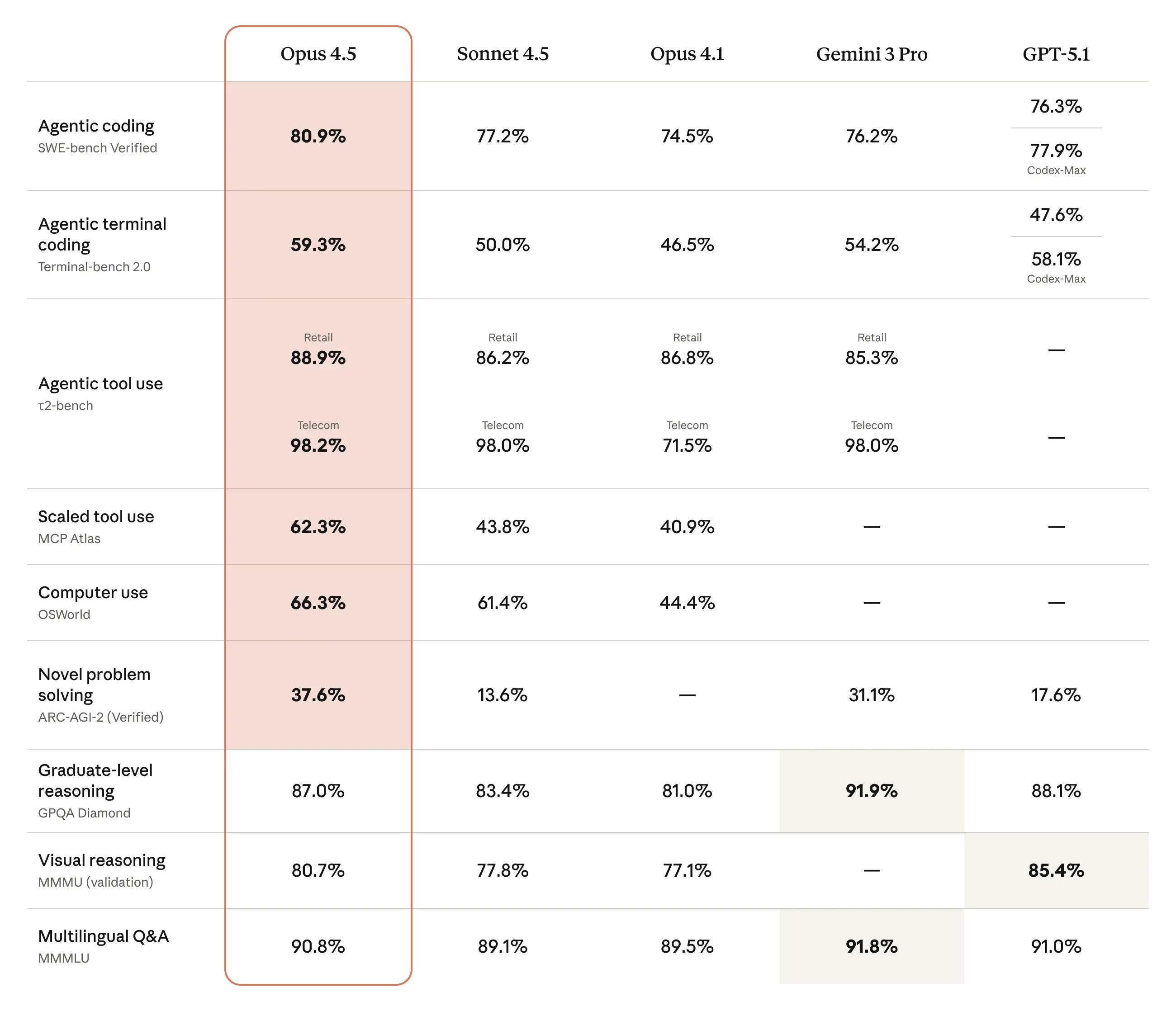
Claude Opus 4.5 demonstrates leadership in key evaluations, outperforming predecessors and peers in efficiency and capability.
SWE-bench Verified (Software Engineering): Achieves state-of-the-art scores among frontier models, surpassing previous benchmarks with 4.3 percentage points improvement over Sonnet 4.5 at high effort.
Users report markedly more natural, contextually rich responses with internal stepwise reflection improving answer correctness and detail. The model shows superior handling of complex instructions with balanced conversational tone and precision.
vs Claude Sonnet 4.5: While Sonnet 4.5 excels in speed for lighter workloads, Opus 4.5's advanced reasoning and token efficiency make it better suited for deep research and multi-agent scenarios, achieving comparable results with up to 76% fewer tokens.
vs Gemini 3 Pro: Claude Opus 4.5 reclaims the edge in specialized benchmarks like software engineering and coding, outperforming Gemini 3 Pro on SWE-bench Verified and agentic tasks with enhanced reasoning depth.
vs Claude 3 Opus: Claude 4.5 Opus significantly advances on its predecessor by incorporating efficiency optimizations and enhanced agentic capabilities, achieving higher scores on SWE-bench and research tasks.
Claude 4.5 Opus sets a new standard in AI performance, focusing on intelligence, efficiency, and practical utility. This model excels in complex tasks like coding, agentic operations, and deep research, while prioritizing robust safety and alignment.
Claude Opus 4.5 demonstrates leadership in key evaluations, outperforming predecessors and peers in efficiency and capability.
SWE-bench Verified (Software Engineering): Achieves state-of-the-art scores among frontier models, surpassing previous benchmarks with 4.3 percentage points improvement over Sonnet 4.5 at high effort.
Users report markedly more natural, contextually rich responses with internal stepwise reflection improving answer correctness and detail. The model shows superior handling of complex instructions with balanced conversational tone and precision.
vs Claude Sonnet 4.5: While Sonnet 4.5 excels in speed for lighter workloads, Opus 4.5's advanced reasoning and token efficiency make it better suited for deep research and multi-agent scenarios, achieving comparable results with up to 76% fewer tokens.
vs Gemini 3 Pro: Claude Opus 4.5 reclaims the edge in specialized benchmarks like software engineering and coding, outperforming Gemini 3 Pro on SWE-bench Verified and agentic tasks with enhanced reasoning depth.
vs Claude 3 Opus: Claude 4.5 Opus significantly advances on its predecessor by incorporating efficiency optimizations and enhanced agentic capabilities, achieving higher scores on SWE-bench and research tasks.





