
256K
0.1107
0.3323
Chat
Inactive
MiMo-V2-Flash
Its long-context capabilities make it an excellent choice for document analysis, knowledge extraction, and large-scale summarization.


Designed for modern AI workloads, MiMo-V2-Flash is equally suited for reasoning-heavy tasks, software engineering, agent orchestration, and large-document understanding.
Xiaomi MiMo-V2-Flash is an advanced, open-source large language model (LLM) developed by Xiaomi’s MiMo team, designed for high-performance AI applications including reasoning, coding, general text generation, and agentic workflows.
MiMo-V2-Flash uses a Mixture-of-Experts (MoE) design. While the model contains hundreds of billions of parameters in total, only a carefully selected subset is activated during inference. This approach enables large-model intelligence with the computational footprint of a much smaller system.
The result is a rare balance: the reasoning depth and representational power of a very large model, combined with the efficiency required for practical deployment in real products.
MiMo-V2-Flash is built for long-form intelligence. With support for context windows up to 256,000 tokens, the model can process entire codebases, extensive technical documentation, multi-chapter reports, or long conversational histories in a single pass.
To achieve this, Xiaomi combines different attention strategies within the same model, ensuring that both local details and global structure are preserved. This makes MiMo-V2-Flash particularly effective for tasks that demand continuity, memory, and deep contextual awareness.
Beyond speed, MiMo-V2-Flash is designed to excel at structured thinking. It performs reliably on complex reasoning tasks, multi-step problem solving, and software engineering workflows. This makes it a strong choice for applications such as code generation, debugging assistance, planning agents, and analytical tools that require consistent logic over long sequences.
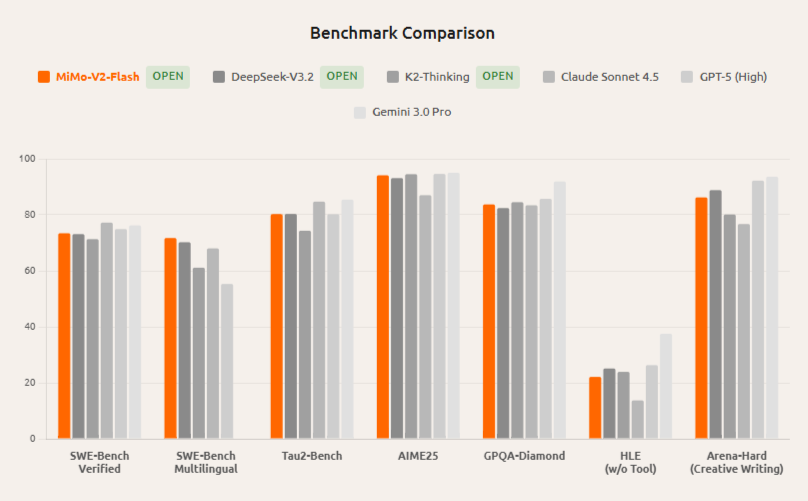
MiMo-V2-Flash matches performance on most reasoning benchmarks with a fraction of active parameters (15B vs. much larger), plus superior long-context results via hybrid SWA. It delivers 3x faster inference at 150 t/s while costing less, making it preferable for high-throughput agentic workflows.
Comparable reasoning scores across math and coding, but MiMo-V2-Flash leads open-source on SWE-Bench Multilingual (71.7%) and agentic tasks. Its MTP boosts speed 2-3x over DeepSeek's denser architecture, ideal for real-time applications.
Approaches Claude's agentic performance (e.g., 73.4% SWE-Bench) as an open-source alternative, with 6x KV savings and MTP for faster deployment. Excels in multilingual coding where Claude shows inconsistencies.
Xiaomi MiMo-V2-Flash is an advanced, open-source large language model (LLM) developed by Xiaomi’s MiMo team, designed for high-performance AI applications including reasoning, coding, general text generation, and agentic workflows.
MiMo-V2-Flash uses a Mixture-of-Experts (MoE) design. While the model contains hundreds of billions of parameters in total, only a carefully selected subset is activated during inference. This approach enables large-model intelligence with the computational footprint of a much smaller system.
The result is a rare balance: the reasoning depth and representational power of a very large model, combined with the efficiency required for practical deployment in real products.
MiMo-V2-Flash is built for long-form intelligence. With support for context windows up to 256,000 tokens, the model can process entire codebases, extensive technical documentation, multi-chapter reports, or long conversational histories in a single pass.
To achieve this, Xiaomi combines different attention strategies within the same model, ensuring that both local details and global structure are preserved. This makes MiMo-V2-Flash particularly effective for tasks that demand continuity, memory, and deep contextual awareness.
Beyond speed, MiMo-V2-Flash is designed to excel at structured thinking. It performs reliably on complex reasoning tasks, multi-step problem solving, and software engineering workflows. This makes it a strong choice for applications such as code generation, debugging assistance, planning agents, and analytical tools that require consistent logic over long sequences.
MiMo-V2-Flash matches performance on most reasoning benchmarks with a fraction of active parameters (15B vs. much larger), plus superior long-context results via hybrid SWA. It delivers 3x faster inference at 150 t/s while costing less, making it preferable for high-throughput agentic workflows.
Comparable reasoning scores across math and coding, but MiMo-V2-Flash leads open-source on SWE-Bench Multilingual (71.7%) and agentic tasks. Its MTP boosts speed 2-3x over DeepSeek's denser architecture, ideal for real-time applications.
Approaches Claude's agentic performance (e.g., 73.4% SWE-Bench) as an open-source alternative, with 6x KV savings and MTP for faster deployment. Excels in multilingual coding where Claude shows inconsistencies.
-min-p-130x130q80.png)





