
Kimi K2.7 Code: The Complete Guide to Moonshot AI's New Open-Weight Coding Model
Quick Facts
What Is Kimi K2.7 Code, Exactly?
Kimi K2.7 Code is an open-weight, coding-focused agentic model built directly on top of Kimi K2.6. "Agentic" is doing a lot of work in that sentence, so let's unpack it. Rather than being tuned mainly for back-and-forth chat, K2.7 Code is shaped around the kind of work a software engineer actually does day to day: reading an unfamiliar repository, planning a multi-file change, running tools and tests, interpreting the output, and adjusting course when something breaks.
Moonshot describes it as their most capable coding model yet, with a specific emphasis on instruction-following across long contexts and higher end-to-end success rates on real software engineering tasks — not just isolated, leetcode-style coding puzzles. The model card and accompanying benchmarks back that framing up with concrete numbers, which we'll get into shortly.
What's notable is the release strategy. Rather than keeping K2.7 Code behind an API wall, Moonshot published the full weights to Hugging Face under a Modified MIT license on day one, alongside support in vLLM and SGLang. At the same time, they paired the release with Kimi Code, a terminal-native coding agent with its own subscription tiers. It's a two-track approach: open model for anyone who wants to self-host or integrate it elsewhere, and a polished first-party agent for people who just want to start coding.
Under the Hood: How Kimi K2.7 Code Is Built
If you're the type who wants to know what's actually happening before you wire a model into your stack, here's the architectural breakdown.
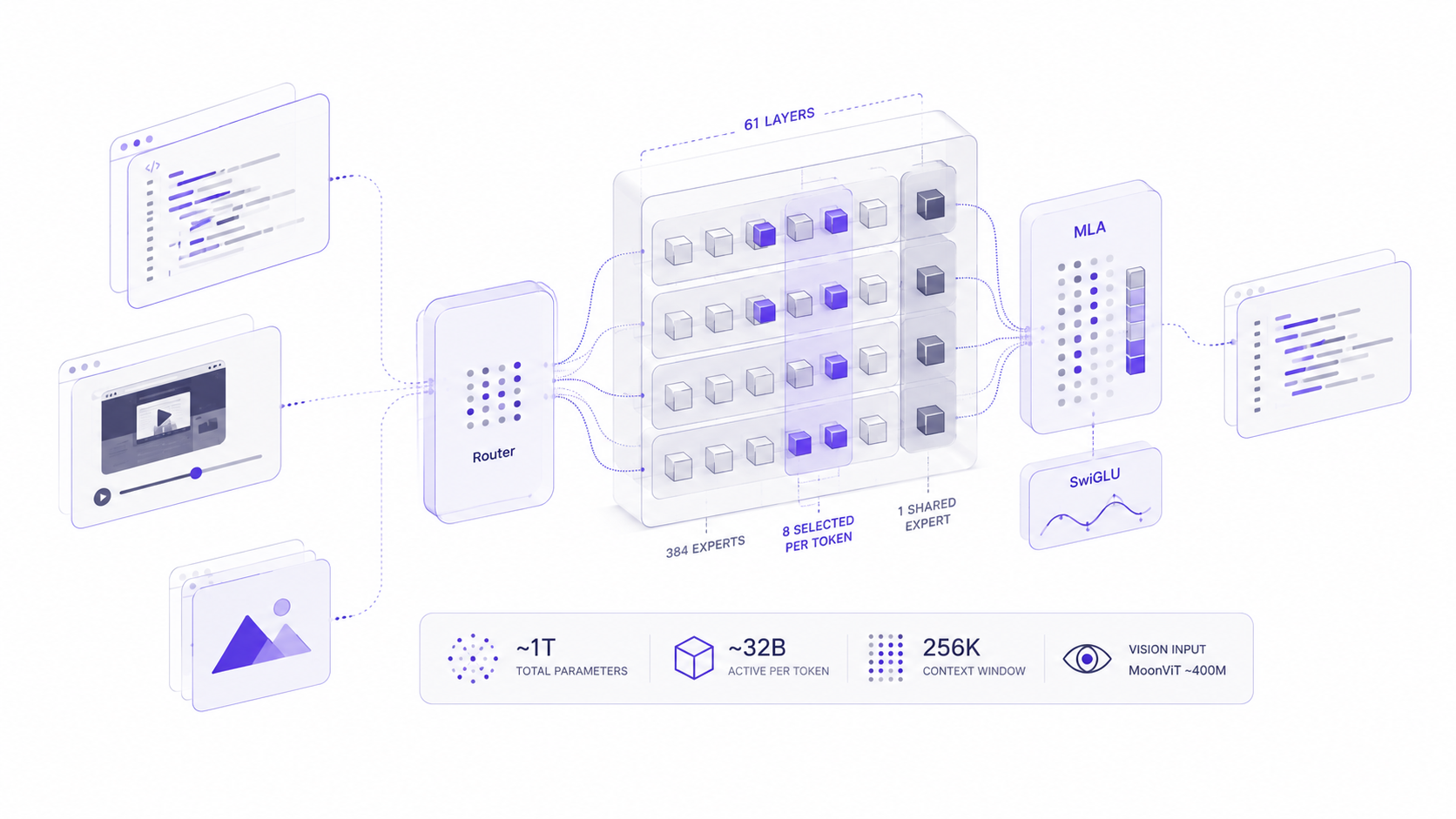
A Trillion Parameters, But Only 32 Billion Doing the Work
K2.7 Code uses a Mixture-of-Experts design with roughly one trillion total parameters, but it only activates around 32 billion of them for any given token. Think of it less like a single enormous brain and more like a large team of specialists where a routing mechanism picks a handful of relevant experts for each piece of the problem. Reports point to 384 experts in total, with 8 selected per token plus 1 shared expert that's always active, spread across 61 layers (60 MoE layers and 1 dense layer).
The practical upshot is that you get the knowledge capacity of a trillion-parameter model without paying the inference cost of running all trillion parameters on every single token. That's a big part of why open-weight MoE models like this one can be priced so much lower than dense frontier models.
Multi-Head Latent Attention and SwiGLU
For the attention mechanism, K2.7 Code uses Multi-head Latent Attention (MLA), which compresses the key-value cache into a smaller latent representation. In plain terms, this helps the model hold onto long conversation and code context without the memory footprint exploding the way it would with vanilla multi-head attention. Combine that with SwiGLU activations in the feed-forward layers — a now-standard choice for high-performing LLMs because it tends to train more stably and generalize better than older activation functions and you get an architecture that's been optimized for both quality and efficiency at scale.
MoonViT: Giving the Model Eyes
K2.7 Code isn't text-only. It ships with MoonViT, a vision encoder weighing in around 400 million parameters, which lets the model accept images and video as input alongside code and text. In practice, this means you could hand it a screenshot of a broken UI, a Figma export, or a short screen recording of a bug reproducing, and ask it to fix the underlying code. The Kimi API documentation even walks through an example where the model watches a video clip via a tool call and reasons about what's happening in specific timestamps — a genuinely useful capability for debugging UI issues or analyzing recorded test runs.
A Context Window Built for Whole Repositories
K2.7 Code, K2.6, and K2.5 all share a 256K-token context window (262,144 tokens, to be exact). That's large enough to load a substantial chunk of a real codebase — multiple files, configuration, documentation, and a long agent transcript — without needing aggressive summarization or chunking tricks. For long-horizon coding tasks, where the model needs to remember decisions it made dozens of steps earlier, that headroom matters a lot more than it sounds on paper.
What Actually Changed Since Kimi K2.6?
K2.6 was already a strong, well-regarded coding model, so the question worth asking is: what did Moonshot actually fix or improve in this update? Based on the model card and release notes, three things stand out.
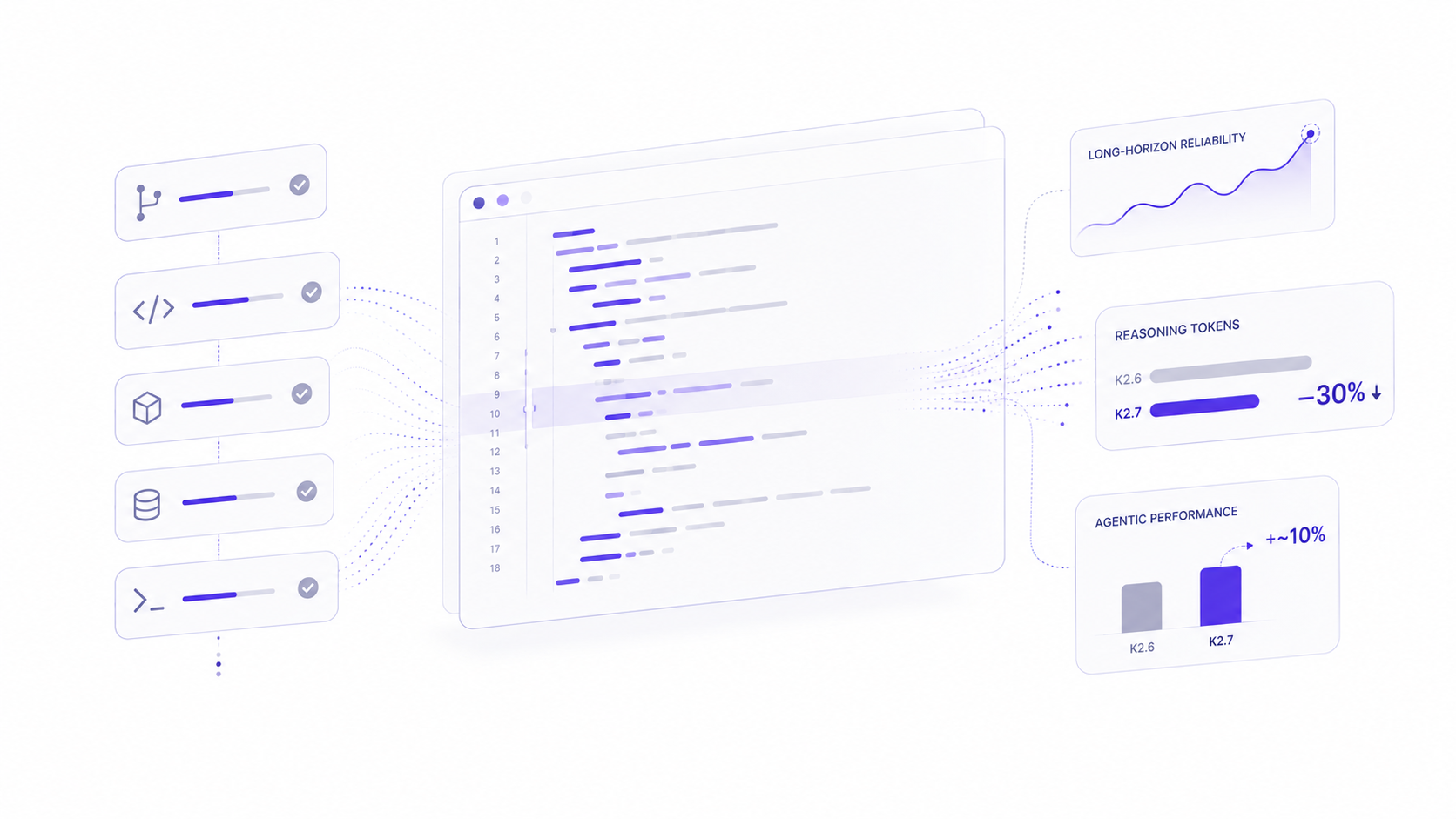
Long-Horizon Coding: Solving the "Great for 10 Steps, Falls Apart at 50" Problem
Anyone who's used an AI coding agent on anything beyond a toy task knows the failure pattern: the model nails the first few steps, then slowly drifts — forgetting an earlier constraint, re-introducing a bug it already fixed, or losing track of which file it's supposed to be editing. Moonshot specifically targeted this with K2.7 Code, and the model card claims a "breakthrough" in long-horizon coding reliability, with more consistent generalization across languages like Rust, Go, and Python, and across task types including frontend development, DevOps automation, and performance tuning.
Practically, that translates to the model following instructions more reliably as a session gets longer, and completing a higher percentage of multi-step tasks all the way to a working result — rather than producing something that looks 90% correct but quietly breaks in production.
Cutting Reasoning-Token Usage by Roughly 30%
Reasoning models have a well-known downside: they can think for a very long time before producing an answer, and all of that internal chain-of-thought costs tokens, which means it costs money and adds latency. Earlier K2 versions reportedly showed signs of "overthinking" on certain tasks, generating long reasoning traces that didn't actually improve the final output.
K2.7 Code addresses this head-on, cutting thinking-token consumption by approximately 30% compared to K2.6 while maintaining or improving output quality. If you're running an agent in a loop hundreds of times a day, a 30% reduction in reasoning tokens is not a rounding error, it's a meaningful chunk of your inference bill and your end-to-end task latency.
Stronger Agentic Performance Across the Board
Better coding ability and better agentic ability tend to go hand in hand, and that's borne out in K2.7 Code's results on agent-focused benchmarks. On Moonshot's in-house agentic evaluations — Kimi Claw 24/7 Bench, plus the MCP Atlas and MCP Mark Verified benchmarks, which test how well a model can use Model Context Protocol tools to complete real tasks — K2.7 Code improves by roughly 10% over K2.6. That's on top of the coding gains, suggesting the improvements aren't isolated to writing code in a vacuum; they carry over into planning, tool selection, and multi-step execution.
Benchmark Numbers: What the Improvements Actually Look Like
Numbers without context are easy to skim past, so here's the headline comparison alongside what each benchmark is actually testing.
Kimi Code Bench v2 and Kimi Claw 24/7 Bench are internal Moonshot benchmarks, designed to mirror realistic engineering and agentic workflows rather than narrow academic problems. Program Bench and MLS Bench Lite add external reference points. The MLS Bench Lite jump is particularly interesting — at 35.1, K2.7 Code reportedly gets close to where GPT-5.5 lands on the same benchmark, which is a notable result for an openly licensed model.
For the head-to-head testing, Moonshot ran K2.7 Code and K2.6 through Kimi Code CLI with thinking enabled, a fixed temperature of 1.0, top-p of 0.95, and the full 262,144-token context. GPT-5.5 was evaluated through Codex in its highest-effort mode, and Claude Opus 4.8 through Claude Code, also at maximum effort. Worth noting: these are first-party, vendor-run numbers at launch, so independent third-party verification is still pending, a sensible thing to keep in mind before basing a procurement decision purely on the model card.
The broader takeaway from the early coverage (including a widely shared comparison on price-per-token) is that K2.7 Code still trails GPT-5.5 and Claude Opus 4.8 on raw coding benchmarks, but by a much smaller margin than you'd expect given the price difference and the price difference is the real story, with K2.7 Code coming in at a fraction of the cost of those closed frontier models.
Where You Can Actually Run Kimi K2.7 Code
One of the nicer things about this release is that Moonshot didn't lock it into a single channel. Here's the rundown of access points.
The Official Kimi API
Through platform.kimi.ai, you can call kimi-k2.7-code via an API that's fully compatible with the OpenAI SDK format, meaning if you've already integrated GPT-style chat completions, switching the model name and base URL is most of the work. The platform also includes a Dev Workbench/playground for testing prompts interactively before you commit to API calls in production.
Kimi Code: The Terminal-Native Coding Agent
Alongside the model, Moonshot ships Kimi Code, an open-source, terminal-first coding agent that you install with a single shell command. It's positioned as a coding-focused perk of Kimi membership, with plans starting around $19/month, and a "6x High-Speed Mode" that's been announced but not yet given a firm release date. If you want something closer to "Claude Code, but pointed at Kimi models," this is that product.
Open Weights on Hugging Face
The full model — weights and all — is published on Hugging Face under a Modified MIT license, with deployment support for vLLM and SGLang. Be prepared for the size, though: the weights reportedly add up to around 595GB, so self-hosting is a serious infrastructure commitment, not a weekend project on a single GPU.
Third-Party Hosts and Aggregators
If you don't want to manage your own API integration or run the model yourself, K2.7 Code is already available through several third-party platforms:
- Ollama — pull
kimi-k2.7-code:cloudand run it through the standard Ollama chat interface, with documented launch commands for tools like Claude Code, Codex, OpenClaw, Hermes Agent, and OpenCode pointed at the Kimi model. - OpenRouter — routes requests to whichever provider currently hosts the model, with Balanced, Nitro, and Exacto routing modes depending on whether you're optimizing for price, speed, or a fixed provider.
- Cloudflare Workers AI — available as a frontier-scale model option for agentic workloads directly from Cloudflare's inference platform.
- AI/ML API — a unified API endpoint that lets you call K2.7 Code (and hundreds of other models) through one OpenAI-compatible interface, which is particularly useful if you're already juggling multiple model providers and don't want a separate integration for each one.
A Note on Locked Parameters
If you're migrating an existing integration to K2.7 Code, there's one quirk worth knowing about upfront: several sampling parameters are fixed and will throw an error if you try to override them.
- Thinking mode can't be disabled — it defaults to
{"type": "enabled"}and the model errors out if you try to turn it off. - Temperature is locked to
1.0. - top_p is locked to
0.95. - n, presence_penalty, and frequency_penalty must stay at their defaults (1, 0.0, and 0.0 respectively).
- tool_choice only accepts
"auto"or"none"— anything else will error. - During multi-step tool calls, you need to preserve
reasoning_contentfrom the assistant's previous turn in the conversation history, or the request will fail.
None of this is a dealbreaker, but if your existing code sets temperature=0 for deterministic output (a common pattern for coding tasks), you'll need to remove that override before pointing it at K2.7 Code.
Pricing: How Much Does Kimi K2.7 Code Actually Cost?
Pricing varies depending on which provider you call the model through, but the consistent theme across every host is that K2.7 Code is dramatically cheaper than the closed frontier models it's being benchmarked against. One widely cited comparison put the price gap at up to 12x versus GPT-5.5 and Claude Opus 4.8, depending on the specific workload and routing.
To give you a concrete reference point, on AI/ML API the pricing structure looks like this:
Price per million tokens
- Input (cache hit): $0.25
- Input (cache miss): $1.24
- Output: $5.20
Compare that to frontier closed models in the same coding-benchmark conversation — GPT-5.5 and Claude Opus 4.8 — which tend to sit several times higher per million tokens for both input and output. For a coding agent that might process tens of thousands of tokens of repository context per task and run dozens of iterations, that multiplier compounds quickly. It's the kind of gap that turns "interesting open-weight model" into "the model our agent actually runs on by default, with the expensive model reserved for the handful of tasks that genuinely need it."
What Kimi K2.7 Code Is Good At And Where It Falls Short
Best Use Cases
AI coding assistants and IDE copilots. The combination of a 256K context window and stronger long-horizon reliability makes K2.7 Code a solid reasoning engine behind repository-aware chat assistants, pull request reviewers, and in-editor copilots that need to understand how a change in one file ripples through others.
Autonomous coding agents. This is arguably the model's home turf. Agent loops — plan, write code, run tests, read the output, adjust — are exactly the workflow Moonshot optimized for, and the reduced reasoning-token overhead means those loops run faster and cheaper at scale.
Enterprise codebase modernization. Because the weights are openly licensed, organizations with data-residency or compliance constraints can self-host K2.7 Code for tasks like legacy code migration, automated documentation generation, and large-scale refactors without sending proprietary code to a third-party API at all.
Open-source and research projects. The Modified MIT license and Hugging Face availability make it a natural base for teams building specialized coding agents, fine-tuning experiments, or academic research into agentic software engineering.
Honest Limitations
It's worth being upfront about the trade-offs. K2.7 Code still trails GPT-5.5 and Claude Opus 4.8 on raw coding benchmarks — it's closing the gap, especially on MLS Bench Lite, but it's not claiming outright superiority. The always-on thinking mode and locked sampling parameters mean less flexibility if your use case genuinely benefits from low-temperature, deterministic output. And while the open weights are a huge plus for some teams, the 595GB footprint puts genuine self-hosting out of reach for most individuals and smaller teams — in practice, most people will access it through an API rather than running it themselves. Finally, since the headline benchmark numbers are vendor-reported at launch, it's reasonable to wait for independent evaluations before treating them as gospel.
Kimi K2.7 Code vs. Kimi K2.6 vs. the Closed Frontier
If you're trying to decide which model fits your project, here's the short version:
Kimi K2.6 remains a well-rounded, general-purpose model — strong at conversation, reasoning, and content generation across mixed workloads. If your application isn't primarily about code, K2.6 (or a similarly general model) may still be the more balanced pick.
Kimi K2.7 Code is the specialist. It gives up some general-purpose breadth in exchange for measurably better long-horizon coding and agentic task completion, lower reasoning-token overhead, and — critically — a price point that makes high-volume agent usage economically realistic.
GPT-5.5 and Claude Opus 4.8 remain ahead on raw coding benchmark scores in Moonshot's own comparisons, particularly in their highest-effort modes. If your task absolutely requires the best possible single-shot output regardless of cost, they're still the models to beat. But for teams running agents thousands of times a day, where the model is one component in a larger pipeline rather than the final word, K2.7 Code's cost-to-performance ratio is hard to ignore.
If everything above sounds useful but the idea of managing yet another API key, billing account, and rate limit makes you tired before you've written a line of code — that's a completely normal reaction, and it's exactly the problem a unified API is meant to solve.
AI/ML API gives you access to Kimi K2.7 Code alongside hundreds of other models — including GPT-5.5, Claude Opus 4.8, and Gemini 3.5 — through a single OpenAI-compatible endpoint and one API key. No separate Moonshot account, no juggling multiple billing dashboards, no rewriting your integration every time you want to try a different model for a task. Just swap the model name and start building.
Get your API key and try Kimi K2.7 Code on AI/ML API
Frequently Asked Questions
Is Kimi K2.7 Code free to use? The model weights are open-source under a Modified MIT license, so self-hosting is technically free of licensing fees — though running a ~595GB model requires substantial GPU infrastructure. Most developers will use it through a paid API (Moonshot's own platform, or third-party hosts like AI/ML API, OpenRouter, or Ollama's cloud models), where pricing is usage-based and significantly lower than comparable closed models.
Can I turn off "thinking" mode if I just want a quick answer? No. Kimi K2.7 Code does not support a non-thinking mode — the thinking parameter defaults to enabled and the API will return an error if you try to disable it. The upside is that the reasoning-token reduction in this version means "always thinking" is noticeably less costly than it was in K2.6.
What programming languages does Kimi K2.7 Code handle best? Moonshot specifically calls out improved generalization across Rust, Go, and Python, along with stronger results in frontend development, DevOps tasks, and performance optimization scenarios. As a general-purpose code model trained on a broad mixture of languages, it's not limited to these, but they're the areas Moonshot highlighted as seeing the biggest gains.
How does Kimi K2.7 Code compare to Claude Opus 4.8 and GPT-5.5 for coding? On Moonshot's own benchmark suite, K2.7 Code trails both models in raw scores, particularly when those models run in their highest-effort modes. However, K2.7 Code is priced dramatically lower — by some estimates up to 12x cheaper per token — which changes the calculus for high-volume, agent-driven workloads where running the most expensive model on every step isn't economically practical.
Can I use Kimi K2.7 Code with tools like Claude Code or other coding agents? Yes. Because the API is OpenAI-compatible, and because Ollama's documented launch commands point directly at tools like Claude Code, Codex, Cline, Roo Code, and OpenCode configured to use kimi-k2.7-code, you can generally swap it into existing agent tooling as the underlying model, subject to the locked-parameter constraints described above.



