
MiniMax M3: The Open-Weight Frontier That Does It All
A Model Built for Agents, Not Just Answers
Most language models are conversation engines — they respond, summarize, and explain. MiniMax M3 is designed to execute. It can run for twelve hours straight, make nearly two thousand tool calls without losing the thread, rewrite a CUDA kernel from first principles, or reproduce a peer-reviewed research paper autonomously — all without a human stepping in to course-correct.
That execution capability comes from three technical pillars working together: a new sparse attention architecture that makes million-token contexts tractable rather than theoretical, frontier-level coding training that pushes state-of-the-art benchmark numbers, and multimodality that's baked into pretraining rather than tacked on afterward.
MiniMax, the Shanghai-based AI company behind models like M2.5, has been positioning itself at the open frontier since its early releases. M3 is the sharpest expression of that ambition yet.
MSA: The Architecture That Makes 1M Tokens Real
Long-context support is a marketing feature in a lot of AI products. You see "128K context" advertised, and in practice the model degrades badly past the first thirty thousand tokens. MiniMax built MSA specifically to fix this at the architectural level, not through prompt compression tricks or retrieval hacks, but by rethinking how attention itself works.

Why Full Attention Breaks at Scale
Standard transformer attention has quadratic computational complexity, double the context length and you quadruple the compute. That's fine at 4K tokens. At 1M tokens, it's completely impractical. Sparse attention mechanisms have existed as workarounds, but earlier approaches like DSA and MoBA partition the key-value cache imprecisely, leaving large gaps in what the model can actually attend to.
- MSA uses block-level KV partitioning with a "KV outer gather Q" operator for contiguous memory access
What MSA Does Differently
MiniMax Sparse Attention partitions the KV cache into blocks with much higher precision than previous methods. Its inner kernel uses KV blocks as the outer loop, aggregating all the query vectors that hit a given block in a single pass, so each block is read from memory exactly once. Under M3's specific head configuration, this produces arithmetic intensity that's over 4× higher than Flash-Sparse-Attention and flash-moba, the two most widely used open-source sparse attention implementations.
In practical terms: at 1 million tokens, M3's per-token compute is just 1/20th of MiniMax's previous-generation architecture. Prefill is more than 9× faster. Decoding is more than 15× faster. And in ablation testing, MSA matches full attention performance on the vast majority of capability benchmarks, meaning the speed gains come at essentially no quality cost
- 9× faster prefill · 15× faster decoding · 1/20th compute at 1M tokens vs. prior gen
1M Token Context Window
The API supports up to 1M tokens with a guaranteed minimum of 512K. Standard-rate billing applies to calls under 512K; long-context rates apply above that threshold. Automatic cache support is built in — no configuration needed.
Native Multimodality
M3 doesn't process images as an afterthought. The entire data pipeline was rebuilt to incorporate image and text in interleaved sequences from pretraining step zero, enabling the kind of deep visual-textual alignment that can parse research paper charts mid-reasoning or read an invoice off a screen.
Togglable Thinking Mode
Reasoning can be switched on or off per request. With thinking enabled, M3 applies extended chain-of-thought reasoning before answering — ideal for complex multi-step problems. With it off, the model responds faster, which suits code completion and conversational use cases. Both modes share the same pricing.
Benchmark Results vs. Frontier Models
M3 was evaluated against GPT-5.5, Gemini 3.1 Pro, and Claude Opus 4.7 across coding, agentic, multimodal, and long-context benchmarks. The picture that emerges: M3 leads on most coding and agent tasks, runs neck-and-neck with Opus 4.7 on several others, and outperforms both GPT-5.5 and Gemini 3.1 Pro on the broadest range of evaluations.
How M3 Stacks Up
Before M3, the combination of frontier coding, million-token context, and native multimodality existed only in closed-source proprietary systems. M3 is the first open-weight model to bring all three together.
What M3 Can Actually Do
Benchmark numbers matter, but they only tell part of the story. The real test of an agentic model is whether it can sustain complex work over long horizons without human intervention. Here are three internal demos that demonstrate what that looks like in practice.
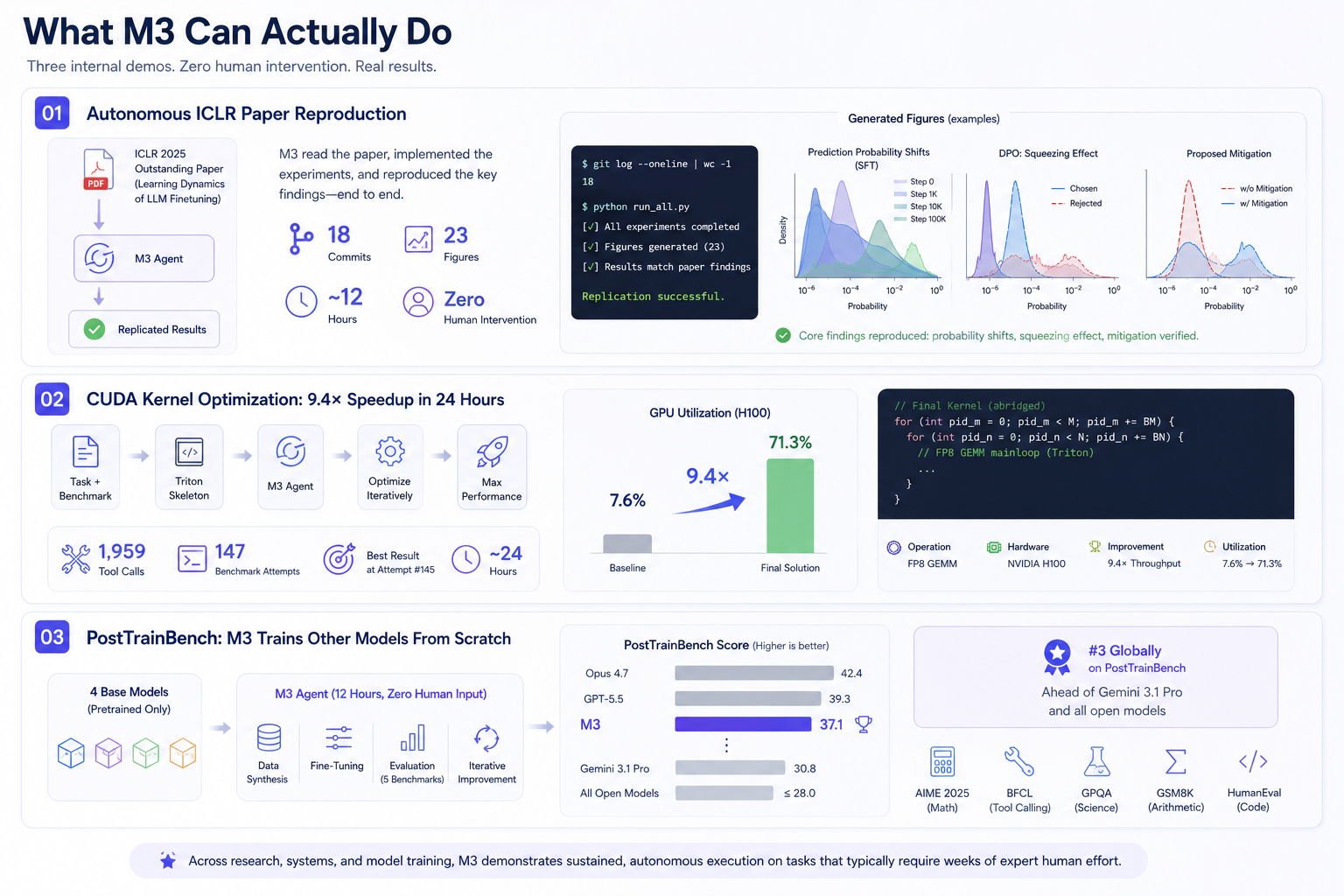
01 Autonomous ICLR Paper Reproduction
MiniMax gave M3 a single PDF — an ICLR 2025 Outstanding Paper Award winner titled Learning Dynamics of LLM Finetuning — and told it to reproduce the experiments independently. No code scaffold, no partial solutions, no human check-ins.
The model ran for nearly twelve hours. In that time it produced 18 Git commits, generated 23 experimental figures, and successfully replicated the paper's core findings: it reproduced the prediction-probability shifts during supervised fine-tuning, confirmed the "squeezing effect" in the DPO experiments, and verified the paper's proposed mitigation approach. Multimodal parsing handled the charts and formulas; the million-token context kept the paper, code, and experiment logs simultaneously in view; and strong agentic capability tied it all together across the full duration.
- 18 commits · 23 figures · ~12 hours · zero human intervention
02 CUDA Kernel Optimization: 9.4× Speedup in 24 Hours
FP8 GEMM, floating-point 8-bit general matrix multiplication, is among the most performance-sensitive operations in large model inference. Getting it right on NVIDIA Hopper GPUs typically takes an experienced team one to two weeks of focused engineering work.
M3 was given a task description, a benchmark script, and a Triton skeleton that couldn't even run directly. No reference implementation. No hints. Just a target: optimize this kernel from first principles. Over roughly 24 hours of continuous execution, M3 made 1,959 tool calls, submitted 147 benchmark attempts, and worked through the entire optimization stack — baseline implementation, autotune configuration, bottleneck diagnosis, CUDA Graph integration, persistent kernel rewriting, and host-side scheduling. Its best solution came on attempt 145. The final result: hardware peak utilization climbed from 7.6% to 71.3%, a 9.4× throughput improvement.
- 7.6% → 71.3% GPU utilization · 1,959 tool calls · best result at attempt #145
03 PostTrainBench: M3 Trains Other Models From Scratch
This one is harder to summarize, because the task itself is unusual: take four base language models that have only completed pretraining and have no downstream capabilities — and teach them to reason. M3 was given 12 hours and zero human input to complete the full pipeline: data synthesis, fine-tuning, evaluation across five benchmarks (AIME 2025 math reasoning, BFCL tool calling, GPQA scientific reasoning, GSM8K arithmetic, and HumanEval code generation), and iterative improvement.
M3 scored 37.1 on PostTrainBench, placing third behind Opus 4.7 (42.4) and GPT-5.5 (39.3) and meaningfully ahead of all other models tested. This is arguably the most demanding real-world agentic task anyone has attempted as a public evaluation — the model has to autonomously decide what data to generate, which training strategy to apply, and how to interpret evaluation results well enough to adjust course in real time.
- #3 globally on PostTrainBench · ahead of Gemini 3.1 Pro, all open models
Works With Your Existing Toolchain
M3 isn't a closed platform you need to migrate your workflow into. It's designed to slot into the tools developers already use for agentic coding — whether that's Claude Code, Cursor, Cline, or any OpenAI-compatible harness. MiniMax calls this "outstanding tool scaffolding generalization," and it's one of the quieter but more practically important aspects of the release.
MiniMax Code: The Full Agent Experience
Alongside M3, MiniMax also shipped MiniMax Code — an agent platform built specifically on top of M3 and co-trained with it. Unlike general-purpose IDEs that use the model as a backend, MiniMax Code is designed from the ground up around M3's capabilities.
Its Agent Team feature decomposes large tasks into multi-stage concurrent workflows, coordinates clusters of agents across those stages, and uses a Producer/Verifier adversarial loop to continuously self-correct. Critically, users can interrupt at any point to add requirements or adjust direction without breaking the agent's momentum. Computer use is also available — M3's native multimodality enables scenarios like reading an invoice on screen and entering it into an ERP system across applications, automatically.
Connecting Via API
The M3 API is OpenAI-compatible and live now. Automatic caching is supported without any configuration on your side. Input pricing is tiered by context length: standard rate for requests up to 512K tokens (which covers almost all conversational and typical coding workloads), and a long-context rate above that for full-repository analysis and ultra-long document parsing.
A priority service tier is also available for SLA-sensitive production deployments — it guarantees scheduling priority and more stable latency under high concurrency conditions.
Model weights will be released on HuggingFace and GitHub shortly, supporting private cluster deployment and fine-tuning.
Who Should Be Using M3 Right Now
Software Engineers Building Agents
If you're building an autonomous coding agent, M3's SWE-Bench Pro and Terminal-Bench performance make it one of the strongest backend choices available. The long context window means the agent can hold entire repositories in view without chunking.
Research Teams Running Experiments
The paper-reproduction demo isn't a party trick — it's a signal that M3 can handle the full research workflow: parsing PDFs, writing code, executing experiments, reading output charts, and iterating. For labs with tight engineering bandwidth, that's genuinely useful.
ML Engineers Working on Inference Optimization
The CUDA kernel optimization benchmark is the clearest evidence yet that an AI model can contribute meaningfully to low-level hardware optimization. M3 isn't replacing performance engineers — but it can run a 24-hour brute-force exploration of the optimization space that no human team would staff.
Developers Who Need Multimodal Context
M3 supports image and video inputs natively — not through a separate vision module, but through the same training run as everything else. If your pipeline involves reading UI screenshots, parsing documents, or understanding video, M3's vision is more tightly integrated than most alternatives.
Cost-Conscious Teams on Frontier Models
At the Token Plan pricing, M3 offers frontier-model performance at a cost structure that's substantially more accessible than closed-source alternatives billed purely per token. For high-volume applications, the math is compelling.
Teams Who Need Deployment Flexibility
With open weights coming to HuggingFace and GitHub, M3 will soon be deployable on private infrastructure. For organizations with data residency requirements or who need fine-tuned variants, that matters enormously.
Access MiniMax M3 Through AI/ML API
AI/ML API provides unified access to MiniMax M3 alongside hundreds of other leading models — OpenAI, Anthropic, Google, and more — through a single API key. One integration. One bill. Full flexibility to switch models as your needs evolve.
Common Questions About MiniMax M3
When was MiniMax M3 released?
MiniMax M3 was officially released on June 1, 2026. It's currently available via API and the MiniMax Token Plan; open-source weights are expected to arrive on HuggingFace and GitHub within days of the initial release.
Is MiniMax M3 truly open-weight?
Open weights are coming but were not available at initial release. MiniMax has committed to releasing model weights on HuggingFace and GitHub, supporting private cluster deployment and fine-tuning. Check the MiniMax HuggingFace page for the latest status.
What's the difference between M3 and M3 with thinking enabled?
Thinking mode switches on extended chain-of-thought reasoning before the model produces its answer. It's better for complex multi-step problems, agent tasks, and long-horizon planning. Without thinking, the model is faster and more suitable for latency-sensitive applications like code completion or chat. The pricing is the same either way — you toggle it per request.
Can I use M3 with tools like Cursor or Claude Code?
Yes. MiniMax explicitly tested M3's compatibility with Claude Code, Cursor, Roo Code, Kilo Code, Cline, Codex CLI, OpenCode, Grok CLI, TRAE, and Droid. If you're already subscribed to a Token Plan, these integrations are available with no additional configuration required.
What does "native multimodality" actually mean in practice?
Most multimodal LLMs work by adding a vision encoder to an existing text-only model after the fact. M3 was trained on interleaved text-and-image data from pretraining step one, meaning visual and textual understanding developed together. This produces better cross-modal reasoning — for instance, M3 can parse a graph in a research paper, understand what it proves, and then write code that validates the same finding, all in a single chain of thought.



