
NVIDIA Nemotron 3 Ultra: The 550B Model Agents Have Been Waiting For
What Is Nemotron 3 Ultra?
Nemotron 3 Ultra is the flagship model in NVIDIA's third-generation Nemotron family, published on June 4, 2026. It sits at the highest tier of a lineup that includes smaller, more specialized variants, and it's the one designed to handle the tasks where getting things wrong is expensive.
At its core, it's a Mixture-of-Experts (MoE) model, meaning it routes each input token through a carefully selected subset of expert networks rather than activating the entire parameter space. The result: a 550-billion-parameter model that behaves computationally like a 55-billion-parameter one.
But parameter counts alone don't tell the full story. What makes Nemotron 3 Ultra genuinely different is the combination of hardware-native quantization (NVFP4), a hybrid Mamba-Transformer attention mechanism, built-in speculative decoding via multi-token prediction layers, and a post-training pipeline that involved more than ten domain-specific teacher models. The result is a model that doesn't just perform well on benchmarks, it's actually designed to work in real multi-step agentic workflows.

Inside the Architecture: Why It Works
Most large models face a fundamental tradeoff: you can make them smarter, or you can make them faster. Nemotron 3 Ultra was built around the thesis that you don't have to choose — if you rethink the architecture from the ground up. Here's what that looks like in practice.
1. Hybrid Mamba-Transformer Design
Standard Transformer attention scales quadratically with sequence length. That's fine for short contexts but becomes prohibitively expensive when agents are juggling thousands of tokens per turn. Nemotron 3 Ultra interleaves Mamba layers — which handle long sequences in linear time — with Transformer layers that provide precise, selective retrieval when exact recall matters. This combination isn't just an engineering compromise; it's genuinely suited to agentic workloads where the model needs to maintain a broad sense of context while being able to zoom in on specific facts.
2. LatentMoE: Smarter Expert Routing
Not all Mixture-of-Experts implementations are equal. NVIDIA's LatentMoE introduces a latent-space routing mechanism that makes expert selection more accurate and context-aware. Rather than making coarse routing decisions early in the process, LatentMoE factors in richer representations before deciding which expert networks should handle a given token. In practice, this means the model can handle workflows that span multiple domains — code generation, tool calls, structured reasoning, domain-specific knowledge — without losing coherence as the task shifts.
3. Multi-Token Prediction (MTP) Layers
Speculative decoding is one of the most effective known techniques for accelerating LLM inference. Most implementations require a separate draft model, which adds complexity and memory overhead. Nemotron 3 Ultra builds multi-token prediction directly into the model architecture as dedicated MTP layers. These layers allow the model to predict several future tokens in parallel, then verify them — natively, without a second model. The practical result is measurably faster generation, particularly in the multi-turn settings that agents rely on most.
4. NVFP4 Quantization: One Checkpoint, Three Architectures
Quantization usually involves painful tradeoffs: smaller storage and faster compute at the cost of accuracy. NVFP4 is NVIDIA's 4-bit floating point format, optimized specifically for their GPU hardware families. The key detail is that the same NVFP4 checkpoint runs on Hopper, Blackwell, and Ampere GPUs without modification. On Blackwell, NVFP4 delivers up to 5× the throughput of BF16 at equivalent quality — a meaningful improvement for any deployment where throughput and cost are real constraints.
5. Reasoning Budget Control
One underappreciated feature: Nemotron 3 Ultra supports explicit control over how much reasoning it performs at inference time. In agent workflows where some steps require deep deliberation and others are routine, this lets developers allocate compute precisely where it matters. You can instruct the model to think harder on ambiguous tasks and move faster on straightforward ones — a capability that directly reduces token consumption and operational cost over the lifetime of a long-running task.
The Post-Training Pipeline That Changed Things
Pretraining gets a model to baseline competence. Post-training is where it develops the judgment to be genuinely useful. Nemotron 3 Ultra's post-training pipeline is unusually elaborate — and that's not an accident.
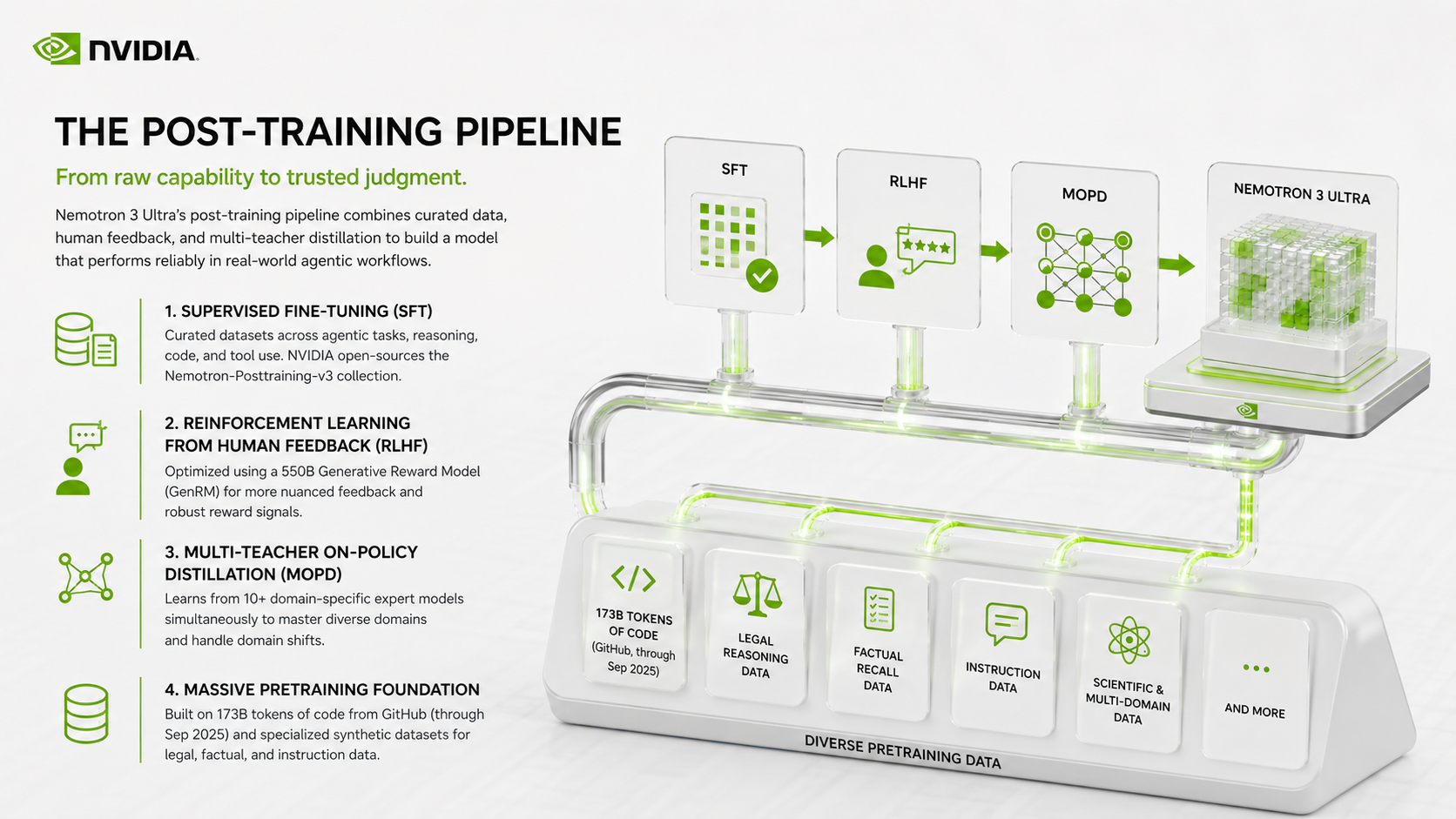
Supervised Fine-Tuning (SFT)
The initial post-training phase uses supervised fine-tuning on a carefully curated collection of datasets spanning agentic tasks, multi-step reasoning, code, and tool use. NVIDIA has open-sourced the Nemotron-Posttraining-v3 dataset collection alongside the model weights, making it possible to inspect and reproduce the training setup.
Reinforcement Learning from Human Feedback
After SFT, the model goes through a reinforcement learning phase. For this, NVIDIA trained a dedicated Generative Reward Model (GenRM) — a 550B model specifically designed to evaluate outputs and provide training signal. Using a model of this scale as a reward model, rather than a smaller classifier, produces more nuanced feedback and avoids some common reward hacking behaviors.
Multi-Teacher On-Policy Distillation (MOPD)
This is perhaps the most interesting part of the pipeline. Rather than distilling from a single teacher, MOPD trains the model using feedback from more than ten domain-specific expert models simultaneously. These teachers cover areas like mathematics, scientific reasoning, coding, legal analysis, and general instruction following. The model learns not just to perform well on average, but to handle domain shifts gracefully, which is exactly what long-running agents encounter when they move between subtasks.
Pretraining Data Scale
The foundation matters too. NVIDIA has released 173 billion tokens of code data from GitHub (through September 2025), specialized synthetic datasets for legal reasoning, factual recall, and diverse instruction formats. This breadth in pretraining shows up in the model's ability to handle professional-domain tasks without fine-tuning.
Benchmark Results: How It Actually Compares
Benchmarks are imperfect, but they're useful for calibrating expectations. Nemotron 3 Ultra was evaluated against three frontier-class open models: GLM 5.1 (744B), Kimi K2.6 (1T), and Qwen 3.5 (397B). The results show a model that holds first place in key agentic tasks while delivering dramatically higher throughput than anything else in the comparison.
A few things worth noting about these numbers. First, Nemotron 3 Ultra is the only model in this comparison that supports up to 1 million token contexts — GLM 5.1 and Kimi K2.6 both cap out at 256K. Its 95% score on RULER at 1M is meaningful because very few models can even attempt that task. Second, the areas where it doesn't lead (coding, long-horizon planning) reflect genuine strengths of Kimi K2.6 and GLM 5.1 respectively — not catastrophic gaps. Third, the raw accuracy numbers don't capture the throughput story: Nemotron 3 Ultra achieves roughly 5× the output speed of GLM 5.1 and Kimi K2.6, which fundamentally changes the economics of running it in production.
- 5.9× Faster than GLM-5.1-754B on 8K/64K token I/O settings
- 4.8× Faster than Kimi K2.6-1T on equivalent workloads
- 1.6× Faster than Qwen3.5-397B in the same settings
- 30% Cost reduction on SWE-bench verified task completion
Where Nemotron 3 Ultra Fits Best
The architecture and post-training choices aren't arbitrary — they point toward specific kinds of work where this model has a genuine advantage. Here's where it makes the most sense to reach for Nemotron 3 Ultra over smaller or faster alternatives.
What NVIDIA Has Released
Nemotron 3 Ultra is fully open — not just the weights, but the datasets and training recipes too. This level of transparency is relatively uncommon at this model scale and reflects a deliberate choice to let the research community build on, fine-tune, and audit the work.
Model Checkpoints
Four distinct checkpoints are available on HuggingFace: the NVFP4 post-trained model for deployment, BF16 post-trained for maximum quality, a BF16 base model for research fine-tuning, and a GenRM reward model.
Training Datasets
173B tokens of GitHub code (through Sep 2025), synthetic legal reasoning datasets, a specialized factual-recall and moral-scenario collection, and the full post-training dataset used for SFT and RL.
Developer Repository
The full training recipe, including NeMo RL and Gym libraries, is available via the NVIDIA-NeMo/Nemotron GitHub repository. This covers the RL pipeline, gym environments, and evaluation harnesses.
Technical Report
A detailed technical report covers the pretraining setup, post-training methodology, architecture choices, and ablation studies. It's the place to go for understanding the design decisions behind the model.
Why This Release Matters Now

We're in a period where the dominant question in LLM deployment has shifted from "can the model do this task?" to "can the model do this task economically enough to be worth deploying?" Frontier model quality has converged enough that throughput, cost, and architectural compatibility now determine which models actually make it into production.
Nemotron 3 Ultra enters this landscape with a clear position: it's the only model in its accuracy tier that achieves 5× faster inference than the next-best comparable option, runs from a single quantized checkpoint across three GPU generations, and supports 1M token contexts without degradation. That combination is harder to achieve than it sounds — most models that optimize for one of those properties compromise on the others.
The open-source commitment adds another dimension. Releasing weights, training data, reward models, and training recipes at this scale gives teams a genuine foundation for domain-specific fine-tuning — not just an API to call. For organizations building specialized agents in healthcare, law, finance, or engineering, having access to the full stack is qualitatively different from having a high-quality black-box endpoint.
Start Building with Nemotron 3 Ultra Today
Get instant access to Nemotron 3 Ultra through AI/ML API — no infrastructure setup, no checkpoint management. Just a clean API for the most capable open reasoning model available.
Common Questions About Nemotron 3 Ultra
How does Nemotron 3 Ultra differ from the other Nemotron 3 models?
Nemotron 3 Ultra is the top tier of the Nemotron 3 family — the final and most capable release. The family includes smaller variants optimized for different cost/capability points, but Ultra is where NVIDIA's full architectural stack (LatentMoE, hybrid Mamba-Transformer, NVFP4, MTP) is used together at maximum scale.
What does "55B active parameters" mean in practice?
In a Mixture-of-Experts architecture, each input token is routed to a small subset of the total expert networks. Nemotron 3 Ultra has 550B parameters total, but only 55B are activated per token — the rest sit idle during that computation. This means the model runs with the compute cost of a 55B model while drawing on knowledge encoded across 550B parameters. The practical implication is that inference is significantly cheaper than the total parameter count suggests.
Do I need NVIDIA Blackwell GPUs to run it?
No — the NVFP4 checkpoint is designed to run on Hopper, Blackwell, and Ampere hardware. The performance gains vary by architecture, with Blackwell delivering the maximum throughput improvement. If you're accessing the model through an API provider like aimlapi.com, the hardware question is abstracted away entirely.
Is Nemotron 3 Ultra actually good for coding tasks?
It scores 54% on Terminal-Bench 2.0, which trails Kimi K2.6 (67%) and GLM 5.1 (64%) on that specific benchmark. However, it produces fewer tokens per turn when completing coding tasks and shows strong instruction-following across multi-turn coding sessions. Whether it's the right choice depends on whether you prioritize raw coding benchmark performance or overall efficiency across a longer agentic workflow.
Can I fine-tune Nemotron 3 Ultra for my domain?
Yes — NVIDIA has released the base checkpoint (BF16) specifically for fine-tuning, along with the pretraining and post-training datasets and the complete training recipe via their GitHub repository. The MOPD methodology used during post-training can also be applied to add new domain teachers during fine-tuning.



