
200K
0.78
2.86
Chat
Active
GLM-4.6 | Zhipu AI
The model’s efficiency and versatility make it ideal for developers and enterprises aiming to deploy advanced AI applications with economic and performance benefits.


GLM-4.6 represents the cutting edge in large language models from Zhipu AI, balancing expansive context capabilities, efficient token use, and strong reasoning performance.
GLM-4.6 is an advanced large language model developed by Zhipu AI (now Z.ai), featuring a state-of-the-art 355 billion parameter Mixture of Experts (MoE) architecture. It is optimized for a broad range of tasks including complex reasoning, coding, writing, and multi-turn dialogue with an extended context window of 200,000 tokens. GLM-4.6 demonstrates industry-leading performance, especially in programming and agentic tasks, making it a top choice for developers and enterprises seeking efficiency and versatility.
GLM-4.6 has been rigorously evaluated across authoritative benchmarks demonstrating competitive or superior results against leading models:
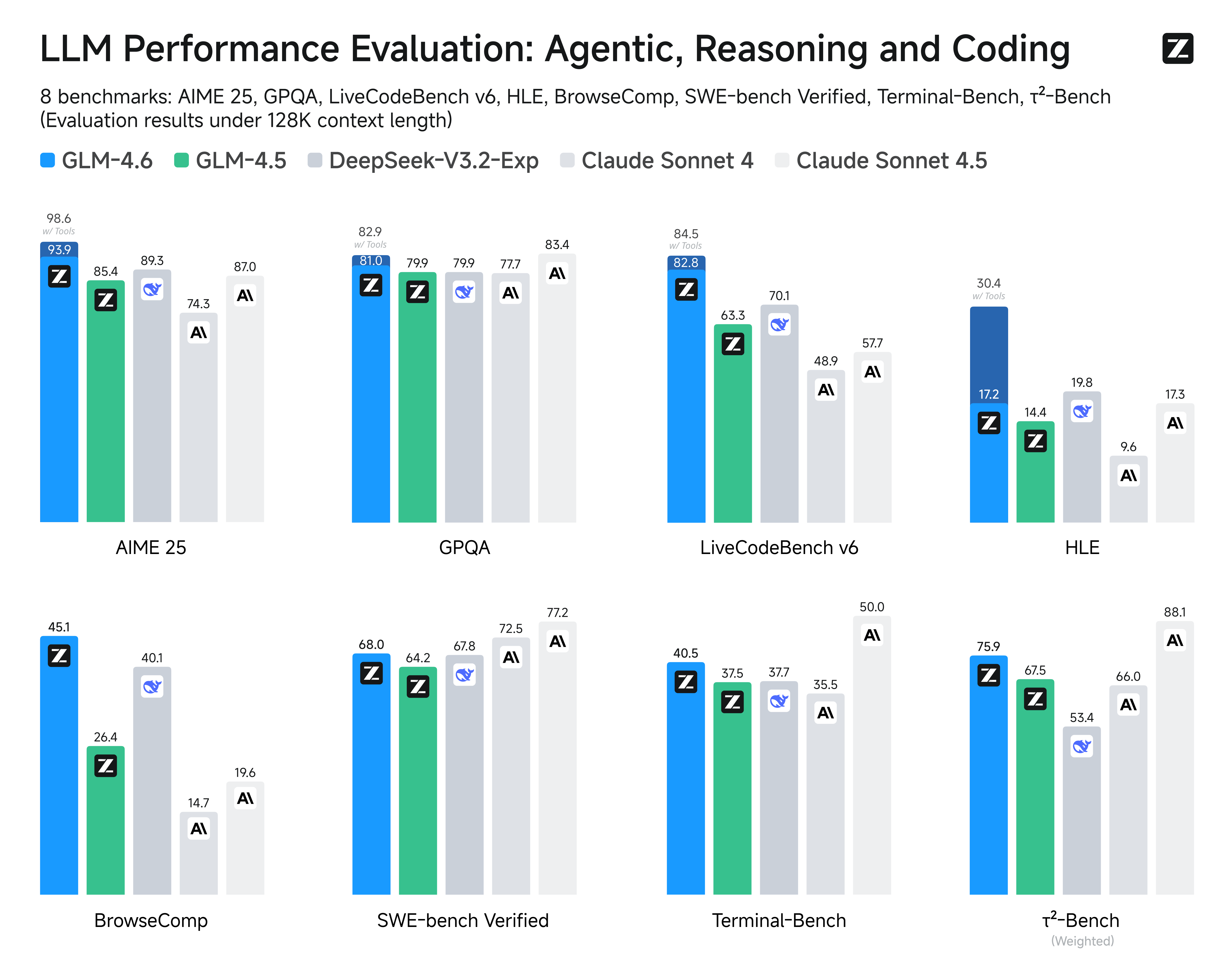
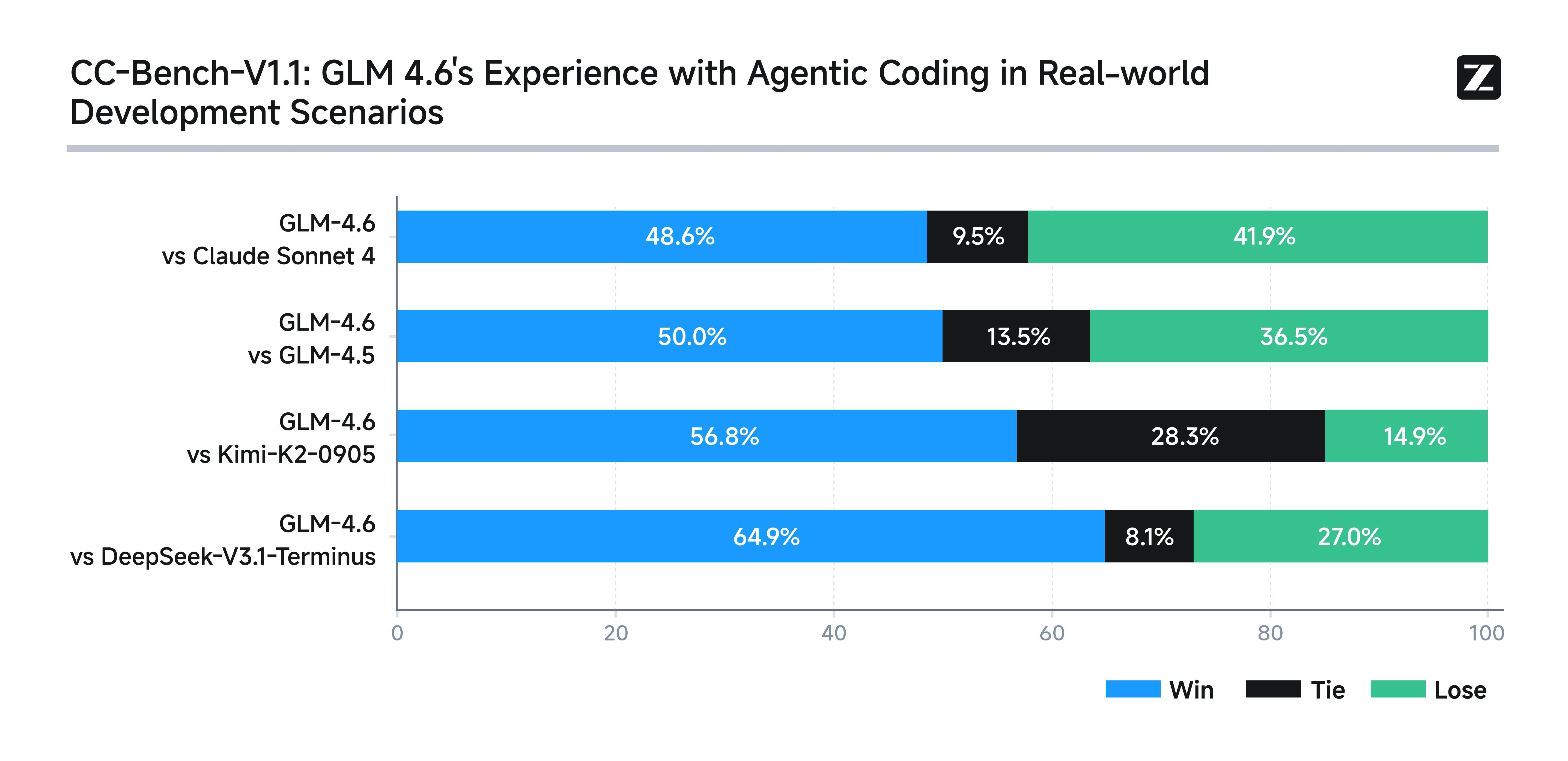
Vs. GLM-4.5: GLM-4.6 offers noticeable improvements in code generation accuracy and maintains a consistent edge in handling ultra-long context inputs, while retaining strong agentic task performance close to GLM-4.5.
Vs. OpenAI GPT-4.5: GLM-4.6 narrows the gap in reasoning and multi-step task accuracy, leveraging its much larger context window; however, GPT-4.5 still leads in raw task precision on some standardized benchmarks.
Vs. Claude 4 Sonnet: While Claude 4 Sonnet excels in coding and multi-agent efficiency, GLM-4.6 matches or surpasses it in agentic reasoning and long-document comprehension, making it stronger for extended-context applications.
Vs. Gemini 2.5 Pro: GLM-4.6 balances advanced reasoning and coding capabilities with enhanced long-form document understanding, whereas Gemini 2.5 Pro is more focused on optimizing individual coding and reasoning benchmarks.
Accessible via AI/ML API. Documentation: available here.
GLM-4.6 is an advanced large language model developed by Zhipu AI (now Z.ai), featuring a state-of-the-art 355 billion parameter Mixture of Experts (MoE) architecture. It is optimized for a broad range of tasks including complex reasoning, coding, writing, and multi-turn dialogue with an extended context window of 200,000 tokens. GLM-4.6 demonstrates industry-leading performance, especially in programming and agentic tasks, making it a top choice for developers and enterprises seeking efficiency and versatility.
GLM-4.6 has been rigorously evaluated across authoritative benchmarks demonstrating competitive or superior results against leading models:
Vs. GLM-4.5: GLM-4.6 offers noticeable improvements in code generation accuracy and maintains a consistent edge in handling ultra-long context inputs, while retaining strong agentic task performance close to GLM-4.5.
Vs. OpenAI GPT-4.5: GLM-4.6 narrows the gap in reasoning and multi-step task accuracy, leveraging its much larger context window; however, GPT-4.5 still leads in raw task precision on some standardized benchmarks.
Vs. Claude 4 Sonnet: While Claude 4 Sonnet excels in coding and multi-agent efficiency, GLM-4.6 matches or surpasses it in agentic reasoning and long-document comprehension, making it stronger for extended-context applications.
Vs. Gemini 2.5 Pro: GLM-4.6 balances advanced reasoning and coding capabilities with enhanced long-form document understanding, whereas Gemini 2.5 Pro is more focused on optimizing individual coding and reasoning benchmarks.
Accessible via AI/ML API. Documentation: available here.





