
256K
0.195
1.56
Chat
Active
Qwen3-Next-80B-A3B Instruct
Its hybrid architectural innovations and extended context support position it well for demanding production scenarios in AI-assisted coding, content generation, and workflow automation.

-p-130x130q80-p-130x130q80.png)
Qwen3-Next-80B-A3B Instruct is a next-generation large language model that balances enormous parameter scale with sparse activation to deliver fast, cost-efficient, and scalable instruction-following capabilities.
Qwen3-Next-80B-A3B Instruct is a highly efficient instruction-tuned large language model designed for fast, stable responses with ultra-long context handling and high throughput. It activates only a small portion of its 80 billion parameters to achieve significant improvements in speed and cost-efficiency without sacrificing performance in reasoning, code generation, and other complex tasks.
Qwen3-Next-80B-A3B Instruct activates only about 3 billion parameters out of 80 billion during inference, making it much faster and cheaper to run — about 10 times faster and more cost-efficient compared to the earlier Qwen3-32B model. It delivers over 10 times higher throughput on long contexts of 32K tokens or more. The model supports flexible deployment options including serverless, on-demand dedicated, and monthly reserved hosting. It is compatible with SGLang and vLLM for deployment with advanced mult-token prediction capabilities, ensuring efficient and scalable usage.
Input: $0.195
Output: $1.56
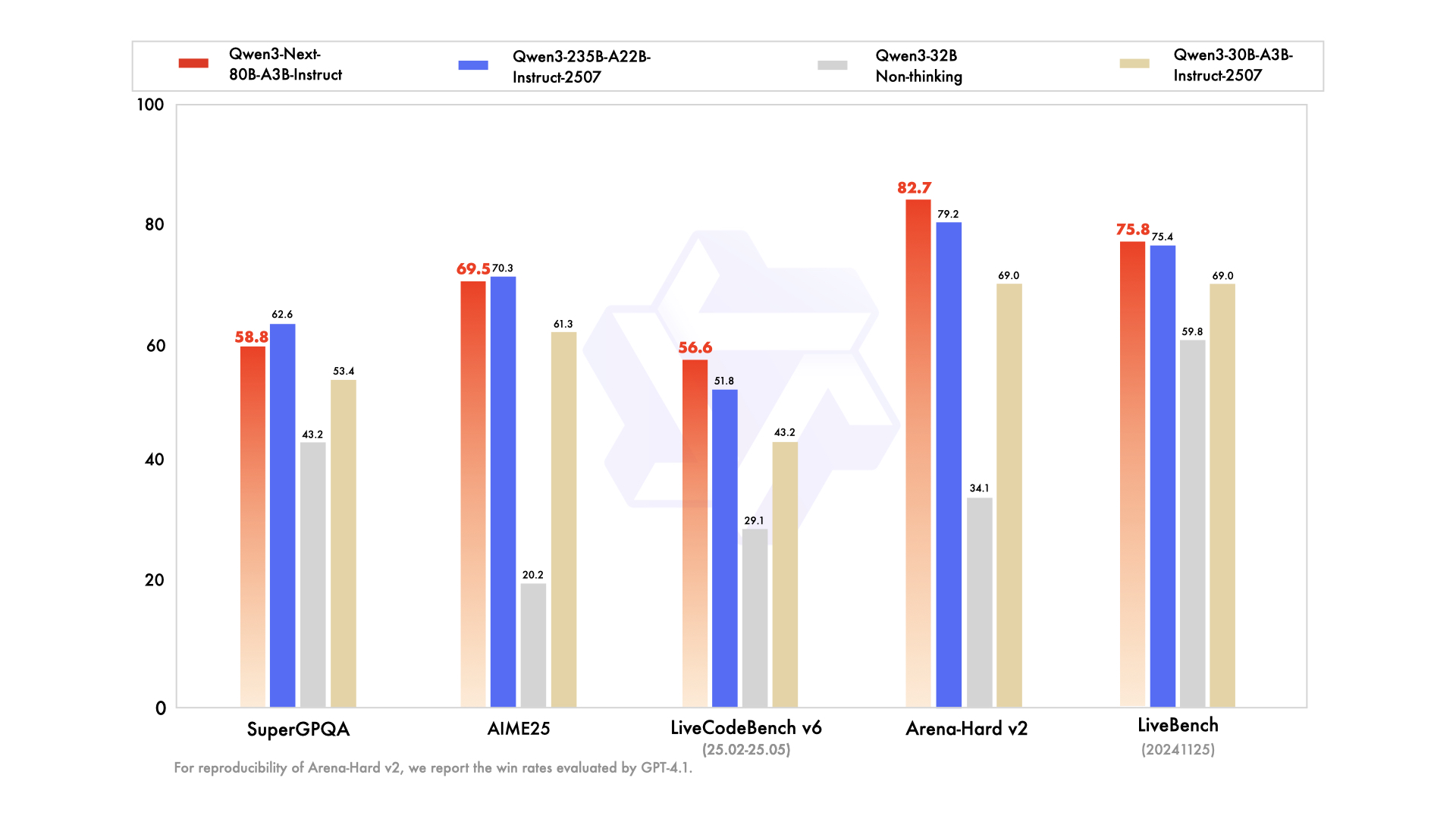
vs Qwen3-235B: The 80B A3B model matches or closely approaches the flagship 235B in reasoning and code tasks but is much more efficient, activating fewer parameters for faster, cheaper inference.
vs GPT-4.1: Qwen3-Next offers comparable instruction-following and long-context capabilities, with an edge in throughput and token window size, making it suitable for extensive document comprehension.
vs Claude 4.1 Opus: Qwen3-Next provides superior performance in multi-turn dialogues and agentic workflows, with more deterministic outputs on very long contexts compared to Claude’s conversational strengths.
vs Gemini 2.5 Flash: Qwen3-Next shows better scaling in ultra-long context handling and multi-token prediction efficiency, giving it an advantage in processing complex, multi-step reasoning tasks.
Qwen3-Next-80B-A3B Instruct is a highly efficient instruction-tuned large language model designed for fast, stable responses with ultra-long context handling and high throughput. It activates only a small portion of its 80 billion parameters to achieve significant improvements in speed and cost-efficiency without sacrificing performance in reasoning, code generation, and other complex tasks.
Qwen3-Next-80B-A3B Instruct activates only about 3 billion parameters out of 80 billion during inference, making it much faster and cheaper to run — about 10 times faster and more cost-efficient compared to the earlier Qwen3-32B model. It delivers over 10 times higher throughput on long contexts of 32K tokens or more. The model supports flexible deployment options including serverless, on-demand dedicated, and monthly reserved hosting. It is compatible with SGLang and vLLM for deployment with advanced mult-token prediction capabilities, ensuring efficient and scalable usage.
Input: $0.195
Output: $1.56
vs Qwen3-235B: The 80B A3B model matches or closely approaches the flagship 235B in reasoning and code tasks but is much more efficient, activating fewer parameters for faster, cheaper inference.
vs GPT-4.1: Qwen3-Next offers comparable instruction-following and long-context capabilities, with an edge in throughput and token window size, making it suitable for extensive document comprehension.
vs Claude 4.1 Opus: Qwen3-Next provides superior performance in multi-turn dialogues and agentic workflows, with more deterministic outputs on very long contexts compared to Claude’s conversational strengths.
vs Gemini 2.5 Flash: Qwen3-Next shows better scaling in ultra-long context handling and multi-token prediction efficiency, giving it an advantage in processing complex, multi-step reasoning tasks.




-min-p-130x130q80.png)

.webp)
.svg)

