
A Better Replicate Alternative for AI Inference (2026)
What is Replicate and where does it fall short?
Replicate is a cloud platform that lets developers run open-source machine learning models via a simple REST API. Its catalog of 50,000+ community-uploaded models, spanning image generation, video, speech, and increasingly LLMs, is genuinely hard to match. For prototyping, weekend projects, and exploring niche models, it's excellent.
The two friction points that push developers toward alternatives are both architectural.
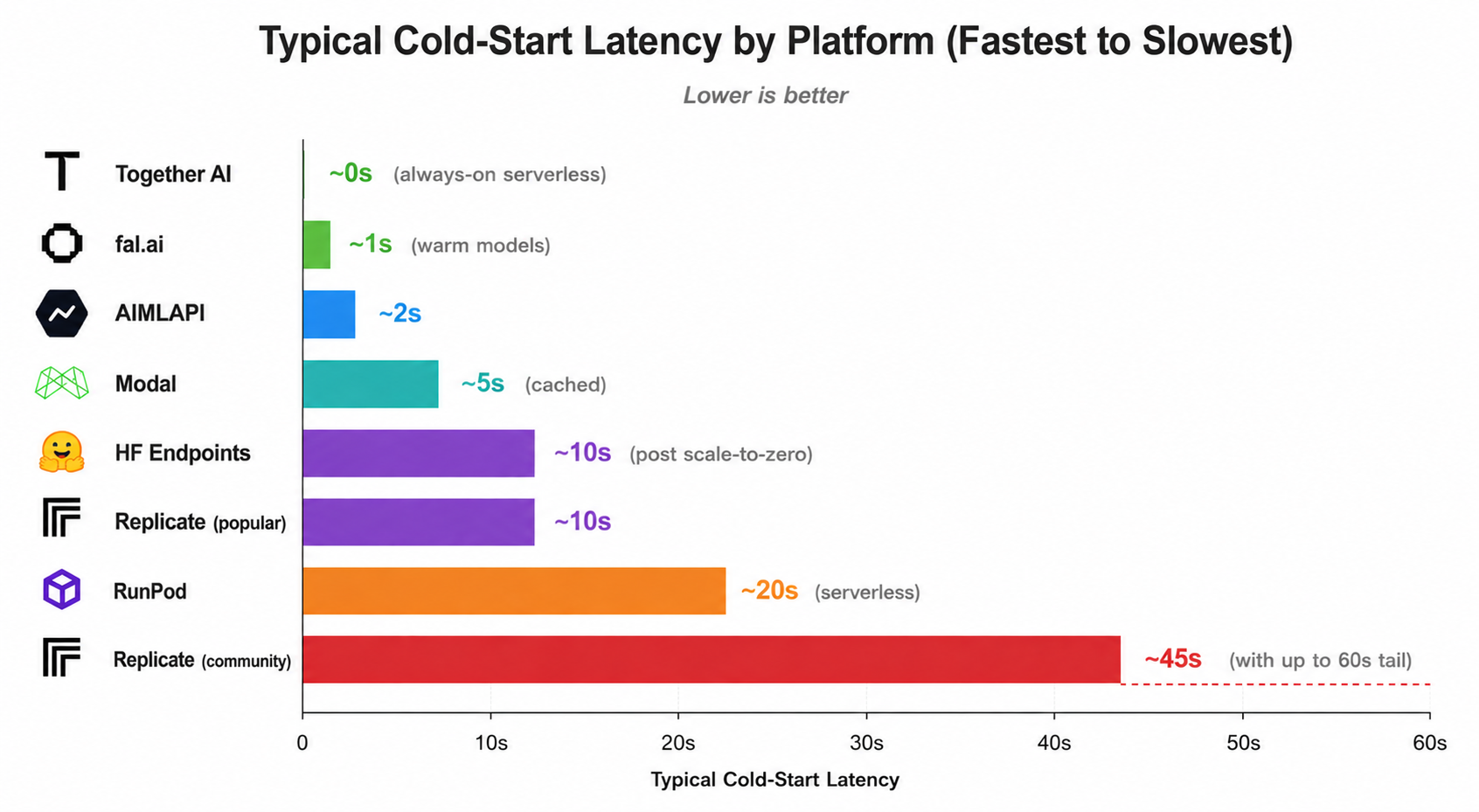
- First: cold-start latency. Replicate runs models serverlessly — if a model hasn't been called recently, it spins down. The next request triggers a cold start, which can range from a few seconds for popular models to 30–60 seconds for less-used community uploads. That's a serious problem in any user-facing product.
- Second: per-second billing. Replicate charges by the second of compute time. For media generation with variable inference time, or LLMs with variable output length, this makes costs difficult to predict. You end up over-budgeting just to handle the variance.
Important context
This article focuses on alternatives that address those two specific pain points. If you genuinely need access to community-uploaded niche models, or want to deploy your own fine-tuned model on shared infrastructure, Replicate may still be your best option, it's unmatched for that use case.
1. AI/ML API — best for predictable billing across modalities
- Best for production billing
- Curated 400+ model catalog with token-based and per-image billing
AI/ML API is a hosted inference platform with a curated catalog of 400+ models — LLMs, image generation, and video — on always-warm infrastructure. The main draw for teams coming from Replicate is the billing structure: LLMs are priced per token (input and output separately), image models per image, and video per second of output. No surprises tied to compute time variance.
Cold starts are effectively not a concern — the infrastructure keeps its catalog warm, so you're paying only for actual inference, not spin-up time. For production apps where user-perceived latency matters, that's a meaningful difference from Replicate's serverless model.
AI/ML API also offers enterprise tiers with SLAs and dedicated support, which is territory Replicate doesn't really occupy. If you're building a commercial product that needs contractual uptime guarantees, that's a genuine differentiator. The trade-off is that AI/ML API's catalog is curated, you won't find niche community-uploaded models here, and you can't deploy your own fine-tuned models.
2. fal.ai — best for fast image and video generation
- Top pick for media
- Serverless GPU platform optimized for media generation
fal.ai is probably Replicate's most direct competitor for image and video generation. It runs 1,000+ models on globally distributed serverless infrastructure with custom CUDA kernels, and the speed difference is noticeable. Sub-second image generation with FLUX, near-zero cold starts on warm models, and WebSocket streaming for real-time output are all standard.
Billing is output-based rather than per-second compute: you pay per image ($0.02–$0.04), per second of video output, or per megapixel. This maps much more cleanly to what your app actually produces. fal.ai also holds a significant share of the image and video generation API market, which means its infrastructure has been battle-tested at scale.
The trade-off is narrow focus. fal.ai is built for media generation. LLM inference is limited, there's no community model publishing, and the catalog is curated rather than open — 1,000 models vs Replicate's 50,000+. If you need broad open-source model access alongside fast media generation, you'll find fal.ai more constrained.
3. Together AI — best for open-source LLM inference
- Best for LLM inference
- Full-stack inference platform for open-source LLMs
Together AI is a strong choice if your primary use case is LLM inference. It offers fast, competitively priced serving for models like Llama, Mixtral, and other popular open-source LLMs, with per-token pricing that makes costs transparent and forecastable. The API is OpenAI-compatible, which means migrating from an OpenAI integration is often just a base URL change.
Beyond serverless inference, Together AI offers dedicated GPU endpoints with guaranteed throughput, GPU cluster provisioning (H100/H200), fine-tuning (full and LoRA), and batch inference at a 50% discount. These are infrastructure capabilities Replicate doesn't emphasize, and they matter for teams that have grown past pure serverless consumption.
The limitation is focus. Together AI is primarily an LLM platform. Image generation exists but is secondary; video is limited. It also doesn't support closed-source models (GPT, Claude, Gemini) or community model publishing. If you need a broad multi-modal catalog, it's not the right fit.
4. Modal — best for Python-first serverless compute
- Best for Python teams
- Infrastructure-as-code serverless GPU platform
Modal takes a different angle entirely. Rather than providing a hosted model catalog, it gives you serverless GPU compute that you define in Python code. You write functions, decorate them with Modal's GPU requirements, and the platform handles scheduling, scaling, and cold-start optimization automatically. Built-in model caching significantly reduces cold starts compared to vanilla serverless.
For teams that want to run their own code and models, not just call a hosted API, Modal is significantly more flexible than Replicate. You can package anything, use any Python library, and control the entire inference stack. The $30/month free tier is generous for experimentation.
The learning curve is real. Modal has its own patterns and abstractions. It's Python-only, so non-Python stacks are excluded. And there's no pre-built model library, you're bringing your own models and packaging them yourself. It's infrastructure tooling, not a marketplace.
5. RunPod — best for budget GPU compute
- Best for raw GPU cost
- Affordable GPU cloud for custom ML workloads
RunPod is the most cost-conscious option on this list. It offers on-demand and spot GPU instances, including A100 and H100, at rates noticeably lower than Replicate's managed equivalents. Spot instances go even cheaper, which suits batch jobs and async workloads that can tolerate interruptions.
There's also a serverless endpoint platform for deploying custom Docker-based models at scale, which gives you Replicate-like API access but with your own models and more hardware control. For teams that have specific GPU requirements or want to maximize cost efficiency on large workloads, RunPod's pricing is hard to beat.
The trade-off is that RunPod requires more setup. There's no pre-built model marketplace, you manage containers, handle dependencies, and build your own deployment pipeline. The developer experience is less polished than Replicate's single-command deploy. It rewards teams comfortable with Docker and infrastructure, and is probably overkill if you just need to call a hosted model.
6. Hugging Face Inference Endpoints — best for dedicated model deployment
- Best model catalog depth
- Dedicated GPU deployment for any Hub model
If Replicate's 50,000 models sounds large, the Hugging Face Hub has over 2 million. Inference Endpoints lets you deploy any of them on dedicated, managed infrastructure with autoscaling and scale-to-zero. The API is OpenAI-compatible, and you can bring custom containers or use Hugging Face's optimized runtimes (TGI for text generation, TEI for embeddings, Diffusers for image/video).
The dedicated infrastructure model means no competing for resources with other users, you get consistent latency and throughput. Private networking (AWS/Azure PrivateLink) and HIPAA compliance make it suitable for regulated workloads that wouldn't fit Replicate. Fine-tuning via AutoTrain or the Transformers library is more flexible than most alternatives.
Cost structure is different from Replicate: you pay per minute of uptime on dedicated hardware, not per prediction. Starting costs (~$0.50/hr for GPU) are manageable but can add up if your model runs idle. Scale-to-zero helps, but if you have bursty or infrequent traffic, Replicate's per-prediction pricing may actually be cheaper.
7. OpenRouter — best for multi-provider LLM routing
- Best for LLM flexibility
- Unified API gateway routing across 60+ providers
OpenRouter routes your API calls to the best available provider across 60+ providers including OpenAI, Anthropic, Google, Meta, and many others. One API key, 300+ models, automatic fallback when a provider has issues, and the ability to set preferences by cost or latency. For teams building on LLMs and wanting to hedge against any single provider, it's a genuinely useful layer.
The API is fully OpenAI-compatible, so existing integrations plug straight in. You can use variant suffixes to fine-tune routing, request the cheapest available provider for a given model, or the fastest, or set specific fallback chains. Pricing is pass-through plus a 5.5% fee on credit purchases.
The boundaries are clear: OpenRouter is for LLMs. Image generation exists but is secondary; video is experimental; audio isn't supported. It's not an infrastructure platform — no fine-tuning, no custom model deployment, no batch jobs. And it doesn't help with the media generation use cases where Replicate shines.
Full comparison table
How the platforms stack up across the key dimensions:
How to choose the right alternative
The right pick depends almost entirely on what you're building. Here's a direct breakdown.
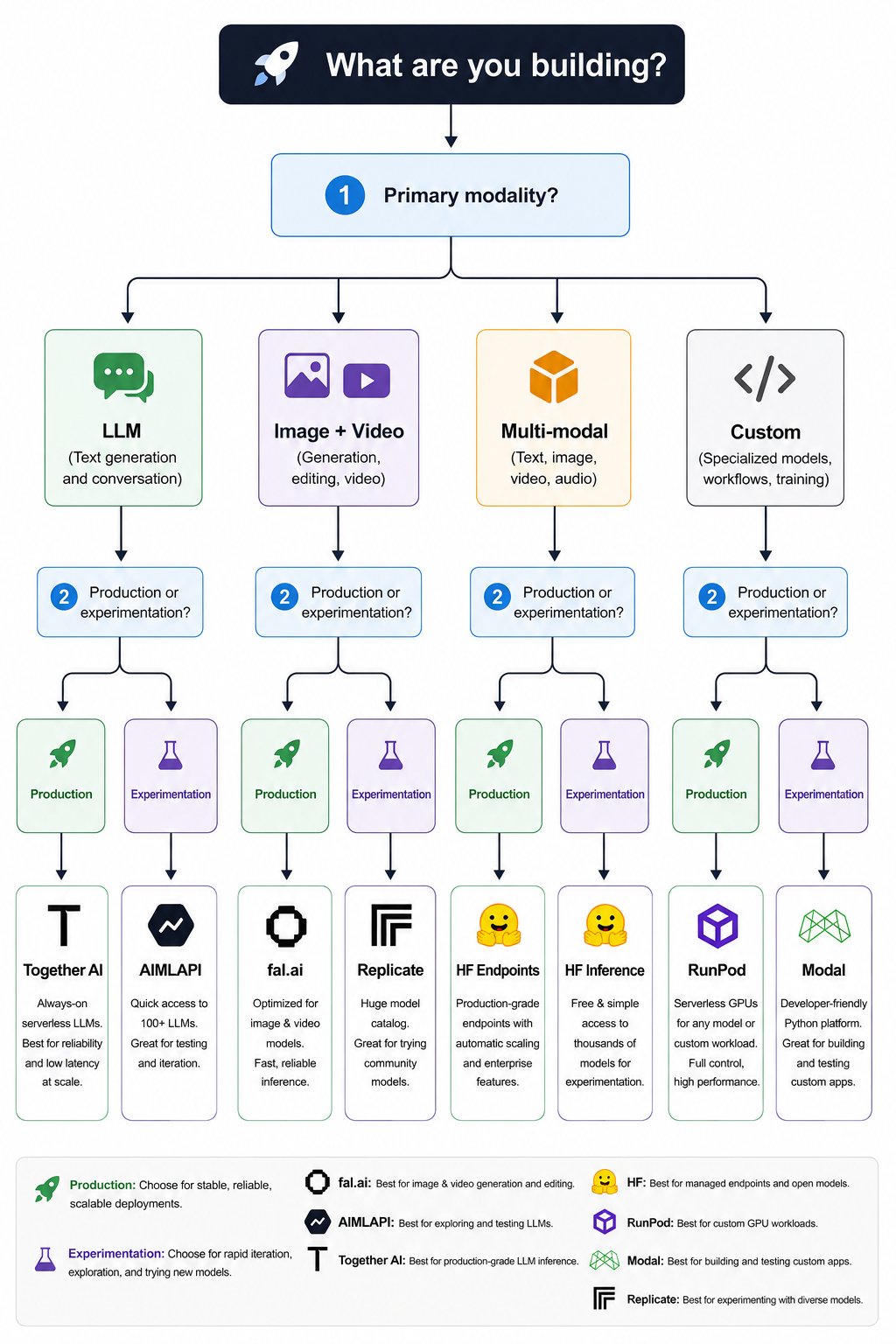
You need fast image or video generation in production
→ Start with fal.ai. Sub-second generation, output-based pricing, near-zero cold starts on warm models. It's built for exactly this workload.
You need predictable costs across LLM + image + video
→ AI/ML API. Per-token LLM billing and per-image pricing across all three modalities, always-warm infrastructure, and enterprise SLA if you need it.
You're building primarily on LLMs
→ Together AI for open-source models at competitive per-token pricing. OpenRouter if you want a multi-provider routing layer with fallback.
You want full control over your inference code
→ Modal (Python teams) or RunPod (Docker-comfortable teams wanting maximum cost efficiency on raw GPU).
You need to host a specific model with dedicated throughput
→ Hugging Face Inference Endpoints. Any of 2M+ Hub models, dedicated hardware, no resource competition, and HIPAA/SOC 2 compliance for regulated workloads.
You still need Replicate's community model catalog
→ Stay on Replicate. If you need niche community-uploaded models or want to deploy your own Cog-packaged model, no alternative matches it for that specific use case.
Frequently asked questions
Is fal.ai faster than Replicate for image generation?
For warm models, yes — often significantly. fal.ai's custom CUDA kernels and optimized GPU infrastructure deliver sub-second generation with models like FLUX. Replicate is more general-purpose and hasn't optimized specifically for media generation throughput in the same way. For cold models, both platforms have similar limitations.
Can I migrate from Replicate to AI/ML API easily?
If you're using models that exist in both catalogs (Stable Diffusion, FLUX, common LLMs), migration is straightforward — update your endpoint, authentication headers, and request body format for the specific models you're calling. For OpenAI-compatible models, it's close to a one-line change. You can't bring community-uploaded or custom models over, so check catalog overlap first.
Which Replicate alternative has the most models?
Hugging Face Hub with 2M+ models is by far the largest repository, though not all are deployable via Inference Endpoints without some setup. For readily callable hosted models, Replicate's 50,000+ still leads among the platforms on this list. fal.ai (1,000+) and AI/ML API (400+) are intentionally curated for production quality over quantity.
Why is Replicate slow on the first request?
Replicate uses serverless inference. When a model hasn't been called recently, it gets scaled down to save resources. The next request to that model triggers a cold start — the model container needs to load back into GPU memory before it can process your input. For popular models, this is often just a second or two. For less-trafficked community models, it can take 30–60 seconds. There's no way to pre-warm models on the standard Replicate tier.



