
The Open Model Family Built for Agentic AI at Scale
Why Nemotron 3 Exists — and Why It Matters Now
Deploying capable AI in production used to mean a constant tradeoff: smarter models were slower, more expensive, and harder to run at scale. You'd either blow your compute budget on a 70B dense model or settle for a smaller model that struggled on multi-step reasoning tasks.
Nemotron 3 is NVIDIA's answer to that problem. Rather than scaling parameters uniformly, NVIDIA leaned into hybrid Mixture-of-Experts (MoE) architecture — a design that keeps only a fraction of parameters active per token, slashing inference cost without sacrificing reasoning quality. The result is a family of models that punch well above their active-parameter weight class.
All three models share a set of core properties: a native 1 million token context window, multi-environment reinforcement learning post-training, configurable reasoning budget control at inference time, and fully open weights, datasets, and training recipes. These aren't just research artifacts — they're engineered for real production deployments, with NVFP4 quantization support, optimized inference for NVIDIA Ampere, Hopper, and Blackwell GPU families, and ready-to-run cookbooks for vLLM, SGLang, and TensorRT-LLM.
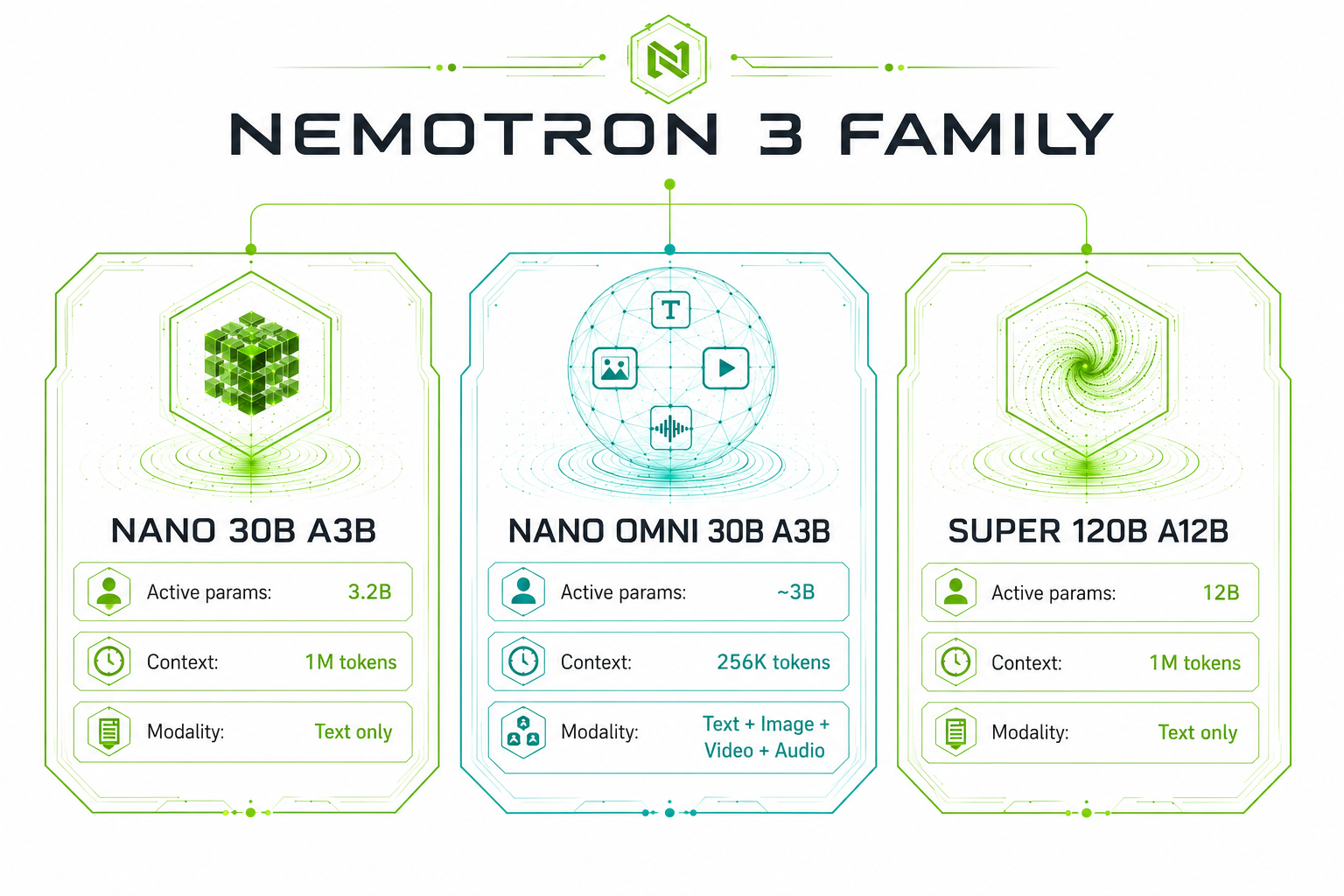
Three Models, Three Roles in Your Agent Stack
Each Nemotron 3 model targets a different position in a multi-agent pipeline. Understanding where each one fits saves you a lot of time when designing your system.
Nemotron 3 Nano 30B A3B
Text · Reasoning
Nano is the workhorse of the family. With only 3.2 billion active parameters per forward pass out of its full 31.6B, it achieves 3.3× higher inference throughput on a single H200 than Qwen3-30B-A3B, while actually outperforming it on benchmark accuracy. It handles text reasoning, coding, math, multi-step tool use, and long-context retrieval — all while being cheap enough to run at scale on a single mid-range server GPU.
Nano was trained on approximately 25 trillion tokens across code, math, science, and general knowledge. Its 52-layer hybrid architecture — 23 Mamba-2 layers, 23 MoE layers, and 6 attention layers — is a ground-up departure from purely transformer-based designs. The Mamba-2 layers handle long sequences efficiently; the MoE layers add specialized depth per token; the attention layers maintain precise cross-token reasoning. Reasoning can be toggled on or off at inference time through the chat template, giving you control over latency/quality tradeoffs.
- Outperforms GPT-OSS-20B and Qwen3-30B-A3B-Thinking on most benchmarks
- 3.3× throughput advantage over Qwen3-30B-A3B on H200
- Configurable reasoning depth at inference time
- Multi-environment RL across math, code, science, tool use
- Supports 20 languages and 43 programming languages
- FP8 and BF16 checkpoints available on Hugging Face
Nemotron 3 Nano Omni 30B A3B
Text · Image · Video · Audio
Nano Omni is what happens when you take Nano's efficient MoE backbone and teach it to see, hear, and watch video. It's NVIDIA's most ambitious model in the family: a single unified architecture that processes text, images, video frames, and audio without needing separate stacks for each modality. This matters enormously for real agentic systems, which routinely need to reason across a screen recording, a document, and a voice note in a single pipeline step.
Under the hood, Nano Omni wraps the Nano LLM with three specialized encoders: C-RADIOv4-H handles high-resolution image and video frames with a tiered patch compression strategy that preserves OCR precision; the NVIDIA Parakeet encoder processes audio inputs, going well beyond simple transcription; and an Efficient Video Sampling (EVS) layer compresses temporal visual tokens so the LLM can reason over long video clips without blowing up its context window. The whole system runs on 3D convolutions to capture motion between frames — something flat image encoders fundamentally cannot do.
Benchmarks from the MediaPerf video industry benchmark show Nano Omni achieving the highest throughput across all task types tested, and the lowest inference cost per video-level tag. On document intelligence leaderboards (MMlongbench-Doc, OCRBenchV2) and multimodal understanding benchmarks (WorldSense, DailyOmni, VoiceBench), it leads among open omni models of comparable size. For video reasoning at a fixed per-user interactivity threshold, NVIDIA reports up to 9.2× greater system capacity versus comparable open omni models.
- Native text, image, video, and audio understanding in one model
- Best-in-class on MMlongbench-Doc and OCRBenchV2
- Up to 9.2× system capacity vs. comparable open omni models
- Efficient Video Sampling (EVS) for low-VRAM video inference
- NVIDIA Parakeet audio encoder for speech understanding
- FP8, NVFP4, and BF16 quantization options
- Supports computer use / GUI agents and document intelligence
- Post-training RL over 25 environment configs, 2.3M rollouts
Nemotron 3 Super 120B A12B
Text · Long-Context · Agentic
Super occupies the high-end slot in the Nemotron 3 family. It addresses two chronic problems that plague long-running agentic systems: context overflow (when the agent forgets what it was doing 100 steps ago) and the "thinking tax" (the compute cost of reasoning at every decision point). Super handles both through its LatentMoE architecture — where tokens are projected into a smaller latent dimension before being routed to experts, calling the inference cost of one expert while effectively engaging the equivalent of four — and a native 1 million token context window that holds an entire workflow in memory without summarization hacks.
Uniquely, Super is the first model in the Nemotron 3 family to be pretrained natively in NVFP4 — NVIDIA's 4-bit floating-point format optimized for Blackwell GPUs. This isn't a post-hoc quantization step; the model learns to be accurate within 4-bit arithmetic constraints from the very first gradient update, which typically preserves quality better than quantizing a full-precision checkpoint afterward. Pretraining ran for over 25 trillion tokens. Inference at 222 tokens per second (median across providers) is roughly 3× faster than competing open models of similar intelligence level.
On PinchBench, a real-world benchmark that evaluates models as the reasoning core inside OpenClaw agents, Super scores 85.6% — the highest of any open model in its class. It supports a 1M-token RULER retrieval score of 91.75, meaning it reliably retrieves relevant information across extremely long inputs. Target workloads include software development automation, IT ticket triaging, cybersecurity incident investigation, long-document research, and any scenario where an agent needs to hold and act on large amounts of context.
- 85.6% on PinchBench — best open model score in its class
- 222 tokens/sec median inference speed across providers
- RULER-100 score of 91.75 at full 1M token context
- LatentMoE: 4-expert intelligence at 1-expert inference cost
- Native NVFP4 pretraining on Blackwell hardware
- Multi-Token Prediction (MTP) layers for faster generation
- 20 languages, 43 programming languages supported
- Runs on a single B200 or DGX Spark with NVFP4
The Architecture Behind the Numbers
All three Nemotron 3 models are built on a hybrid Mamba-Transformer Mixture-of-Experts backbone, but each introduces additional architectural refinements. Here's what actually makes these models work.
Mamba-2 Layers
State space model layers that process sequences with linear (not quadratic) time complexity relative to sequence length. This is what makes a 1M-token context window practical rather than theoretical — the per-token compute cost doesn't explode as context grows.
Latent MoE Layers
Tokens are projected into a smaller latent space before expert routing. This dramatically reduces the bandwidth cost of MoE routing while maintaining diverse specialization across experts. Super's LatentMoE activates four experts at the inference cost of one.
Attention Layers (GQA)
A smaller set of grouped-query attention layers handles cross-token reasoning that Mamba-2 isn't designed for. Nano uses 6 such layers out of its 52 total — enough for precise contextual reasoning without dominating the compute budget.
Multi-Token Prediction (MTP)
Super adds MTP layers that allow the model to predict multiple output tokens simultaneously, improving generation throughput and final output quality. This technique has become increasingly common in frontier models and contributes to Super's exceptional inference speed.
Multimodal Encoders (Omni)
Nano Omni integrates C-RADIOv4-H for vision, NVIDIA Parakeet for audio, and a 3D convolutional video encoder with EVS token compression. These wrap around the same Mamba-Transformer LLM backbone, preserving language model capability while extending it to rich media.
NVFP4 Native Pretraining
Super trains from the very first gradient update in NVFP4 — NVIDIA's 4-bit floating-point format for Blackwell. Unlike post-hoc quantization, the model learns accuracy constraints during pretraining itself, delivering better quality-per-bit than quantized variants of full-precision models.
How They Perform in Practice
Benchmark numbers only tell part of the story — throughput and cost matter as much as raw accuracy. Here's where Nemotron 3 models stand relative to peers.
Nemotron 3 Nano — vs. Comparable 30B-Class Models
Nemotron 3 Super — Intelligence Index (Artificial Analysis)
Nemotron 3 Nano Omni — System Capacity vs. Competing Open Omni Models
What You Can Actually Build with These Models
The Nemotron 3 family was designed with specific deployment scenarios in mind. Here's a non-exhaustive map of where each model tends to shine.
Software Dev Automation
Super's 85.6% PinchBench score makes it the leading open model for coding agents — debugging, code generation, repo navigation, and automated PR review at scale.
Document Intelligence
Nano Omni tops OCRBenchV2 and MMlongbench-Doc. Multi-column layouts, LaTeX tables, reading-order reconstruction — it handles the edge cases that simpler VLMs miss.
Video & Media Analysis
Nano Omni's native video pipeline — 3D convolutions + EVS — enables accurate temporal reasoning across meeting recordings, training videos, and M&E assets.
Cybersecurity Triaging
Super was explicitly tuned for security workflows. Its million-token context can hold an entire incident log in working memory while planning remediation steps.
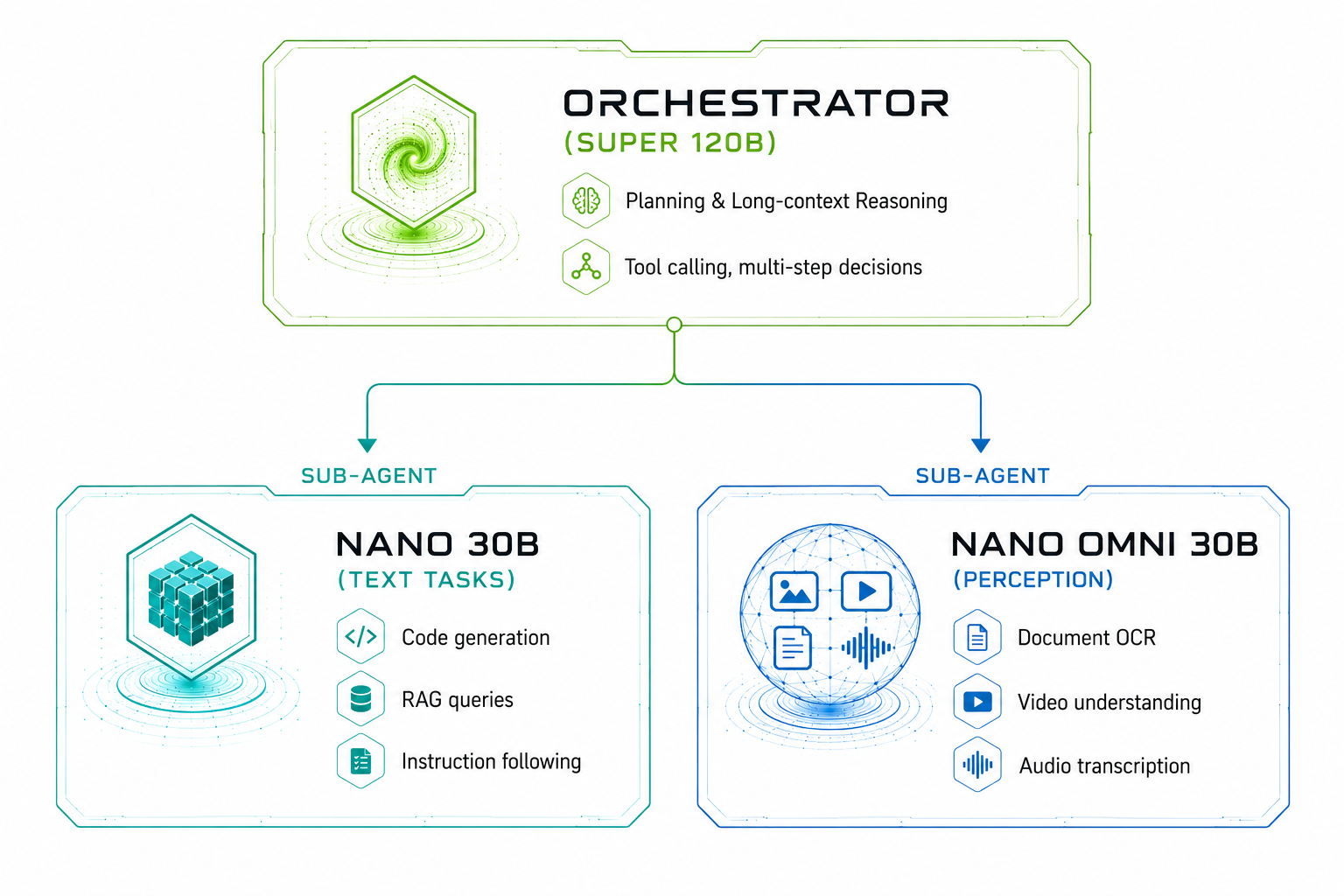
Multi-Agent Orchestration
All three models are designed to integrate cleanly. Nano handles high-volume sub-tasks; Nano Omni manages perception; Super drives planning and long-range reasoning.
Healthcare & Science
Super's broad pretraining corpus spans legal, medical, and scientific domains. Combined with its long context and reasoning depth, it's a strong fit for evidence synthesis tasks.
RAG Systems
Both Nano and Super natively support long-range retrieval and multi-document aggregation. Nano's efficiency makes it practical for high-query-volume RAG pipelines.
Computer Use Agents
Nano Omni includes GUI and screenshot understanding, enabling agents that navigate desktop interfaces, fill forms, and respond to visual UI state changes.
IT Helpdesk Automation
Super is explicitly optimized for IT ticket automation workflows — parsing, classifying, routing, and drafting resolution responses across high-volume queues.
Start Calling Nemotron 3 in Minutes
AI/ML API gives you immediate API access to Nemotron 3 models through a single OpenAI-compatible endpoint. No GPU provisioning, no infrastructure setup. AI/ML API hosts 400+ models behind a unified API interface, so you can benchmark Nemotron 3 Super against other frontier models without switching SDKs or managing separate credentials.



