
What Claude Sonnet 5 Could Bring to Developers and Teams
Why Claude Sonnet 5 matters to developers and teams
Every major AI model release carries weight these days, but a Sonnet release carries a particular kind of weight. For Anthropic, the Sonnet tier has always represented the core of their commercial offering: powerful enough for serious work, fast enough for real-time applications, and priced accessibly enough to deploy at scale. When Sonnet gets better, it does not just move a benchmark number. It changes what's practical for the engineers, product teams, and researchers who rely on it daily.
Claude Sonnet 4.5 was a genuinely strong model, widely regarded as a capable, well-rounded performer for coding assistance, document analysis, and agentic workflows. But the competitive landscape has moved quickly. OpenAI, Google, and xAI have all pushed their mid-tier models harder in recent months, and the pressure on Anthropic to deliver a meaningful leap with Sonnet 5 is real.
Expected improvements in performance
The most obvious question anyone asks about a new model is simple: will it be smarter? With Sonnet 5, the answer almost certainly has to be yes, but the more interesting question is where that intelligence lands.
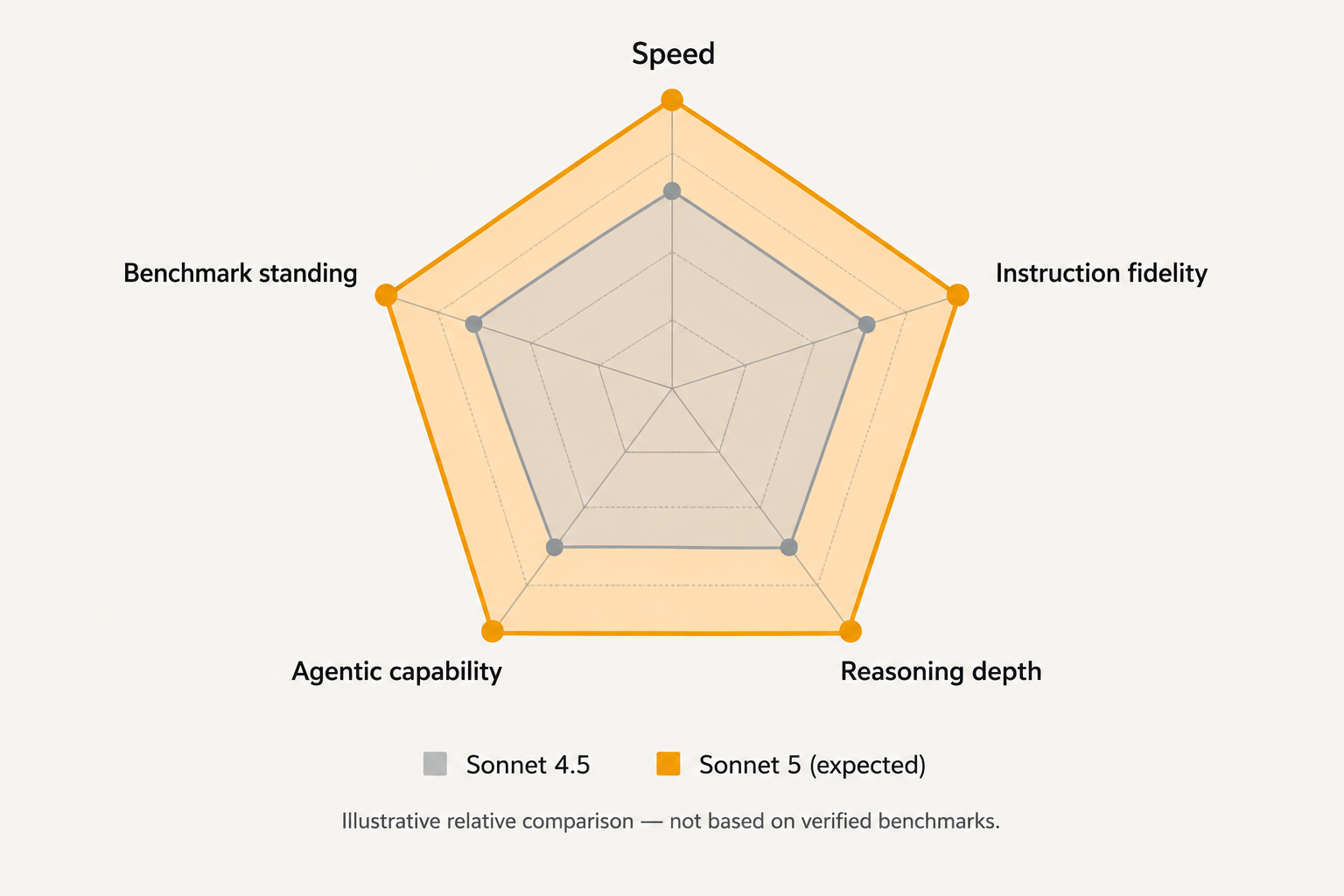
Closing the gap with Opus
With each generation, the Sonnet tier has crept closer to the performance of the previous Opus model. Claude Sonnet 4.5 already approached Opus 4 on a number of reasoning and language benchmarks. If that trajectory holds, Sonnet 5 could offer near-Opus-4 quality at a fraction of the price and latency, which is arguably one of the most commercially significant things Anthropic could deliver.
Better instruction following
One area where mid-tier models still frustrate users is instruction fidelity — the model's ability to follow complex, layered instructions without drifting, adding unsolicited commentary, or dropping format requirements mid-response. Sonnet 5 is widely expected to improve here, particularly for structured output tasks, constrained generation, and multi-turn workflows where the system prompt needs to stay consistently active across long conversations.
Stronger reasoning across domains
Mathematical reasoning, logical inference, and multi-step problem solving have all become competitive markers. Sonnet 5 should push further in these areas, not just to compete with Gemini or GPT, but because Anthropic's own internal research direction, particularly around extended thinking and deliberate reasoning, points clearly toward deeper, more transparent cognitive processes in their next generation of models.
Better coding and developer workflows
Anthropic has made its intentions clear: the developer tooling ecosystem around Claude is a strategic priority. Claude Code, the command-line coding agent, is not a side project — it is a signal. It tells you something about where the company believes the highest-value applications of its models sit. Sonnet 5 will almost certainly be the engine underneath much of that vision.
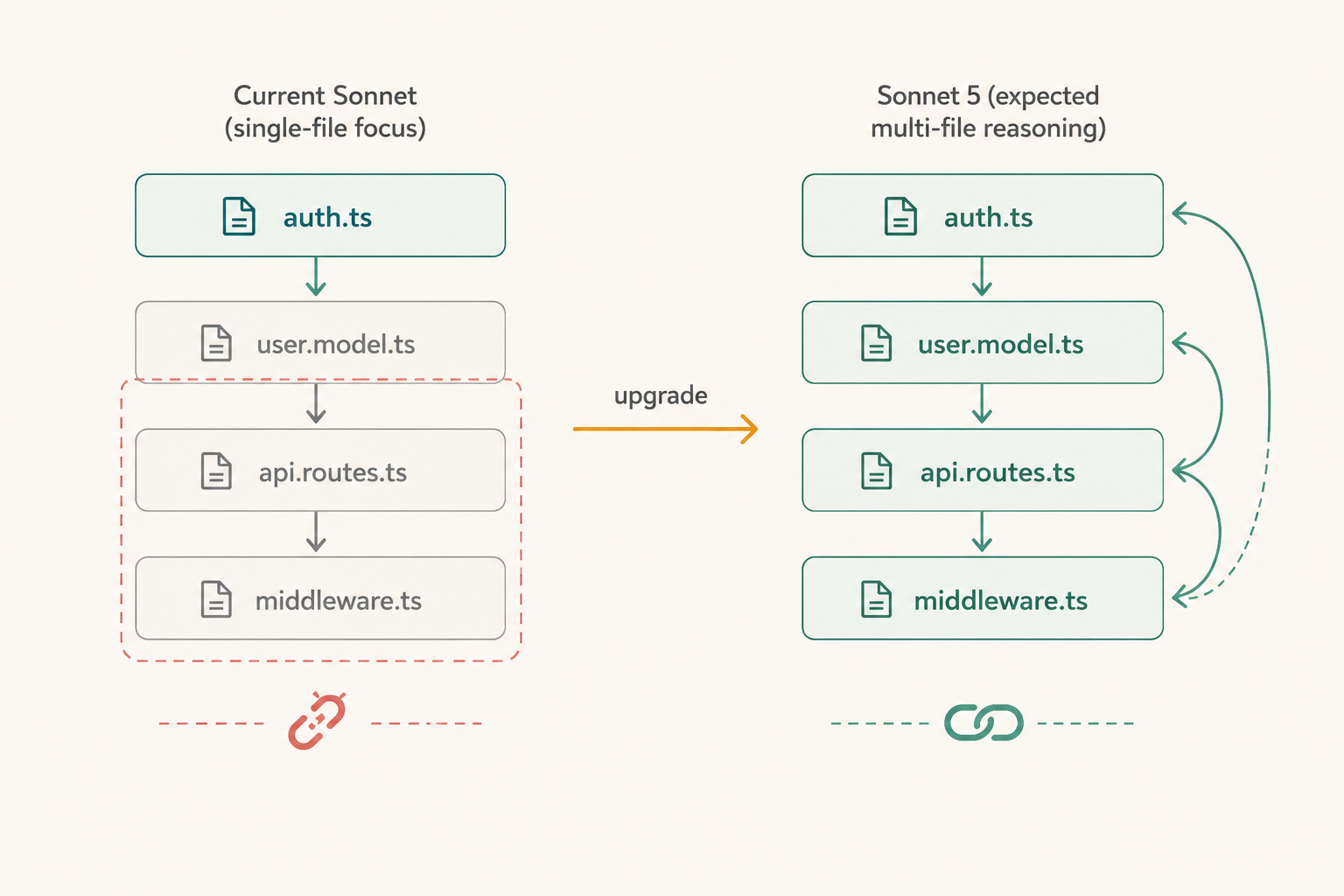
What to expect from Sonnet 5 for coding
Current Sonnet models are already strong at code generation and bug diagnosis. The expected improvements with Sonnet 5 go further: better handling of large codebases, more accurate multi-file reasoning, and stronger ability to navigate unfamiliar libraries or architectural patterns. When you ask a current model to refactor a complex module, it will often succeed, but it can lose coherence when the change ripples across files. Sonnet 5 should handle that propagation more reliably.
Debugging is another area ripe for improvement. The difference between a model that identifies the proximate cause of a bug and one that understands the systemic conditions that allowed it to happen is enormous in practice. Developers who have worked with frontier-tier coding assistants have noticed this gap. Sonnet 5 is expected to reason more causally about code behavior, not just pattern-match on error messages.
Claude Code and team workflows
For teams using Claude Code specifically, Sonnet 5 matters because of how agentic coding tasks scale. A single debugging session is manageable even with a somewhat weaker model. But when you are asking Claude to work through a pull request, run tests, interpret failures, and propose fixes iteratively, every incremental capability improvement multiplies. Better context handling means fewer derailments. Better instruction following means fewer corrections. That compounds quickly across a team's workday.
Why this matters for Claude Code
Claude Code is currently one of the most practically capable coding agents on the market, but its power is bounded by the underlying model. Sonnet 5's expected improvements in multi-file reasoning, tool use, and long-task continuity will directly translate into Claude Code being more reliable for complex, repo-level tasks — not just isolated snippets.
Context, memory, and long conversations
Context length is one of those technical specifications that sounds abstract until you work at the edge of it. Then it becomes viscerally important. Running out of context mid-session means re-establishing state, re-explaining background, and losing the thread of complex reasoning. For teams doing deep technical work, that friction adds up fast.
Why context length matters in real work
For a developer analyzing a large codebase, a long context means the model can hold the entire relevant file structure in its working attention. For a researcher synthesizing multiple papers, it means no loss of detail when moving between sources. For a customer support system, it means a model that genuinely remembers what the user said twelve messages ago without hallucinating or compressing it away. These are not edge cases — they are everyday professional scenarios.
Sonnet 4.6 already supports a generous context window. Sonnet 5 is expected to either extend that further or, potentially more meaningfully, make better use of the context it already has. Utilizing 180,000 tokens is technically possible today; utilizing them well, with equal attention and retrieval quality across the full span, is still an open technical challenge. Improved context utilization could matter more than a raw increase in token limits.
Project continuity
One of the quieter improvements to watch for is how Sonnet 5 handles long-task continuity — the ability to maintain a coherent thread of reasoning across a session with many tool calls, pivots, and intermediate results. This is especially relevant for agentic workflows. A model that can keep track of where it is in a multi-step plan, what it has already verified, and what still needs attention produces qualitatively better outcomes than one that needs constant hand-holding to stay on course.
Agentic features and workflow automation
The word "agentic" gets thrown around loosely in AI coverage, so let's be precise. An agentic AI system is one that can take sequences of actions — using tools, making decisions, adapting to intermediate results — to accomplish a goal that a human has set but did not manually step through. It's the difference between asking Claude to summarize an email and asking Claude to read your inbox, identify action items, draft responses, and add events to your calendar. Both are useful. Only one is agentic.
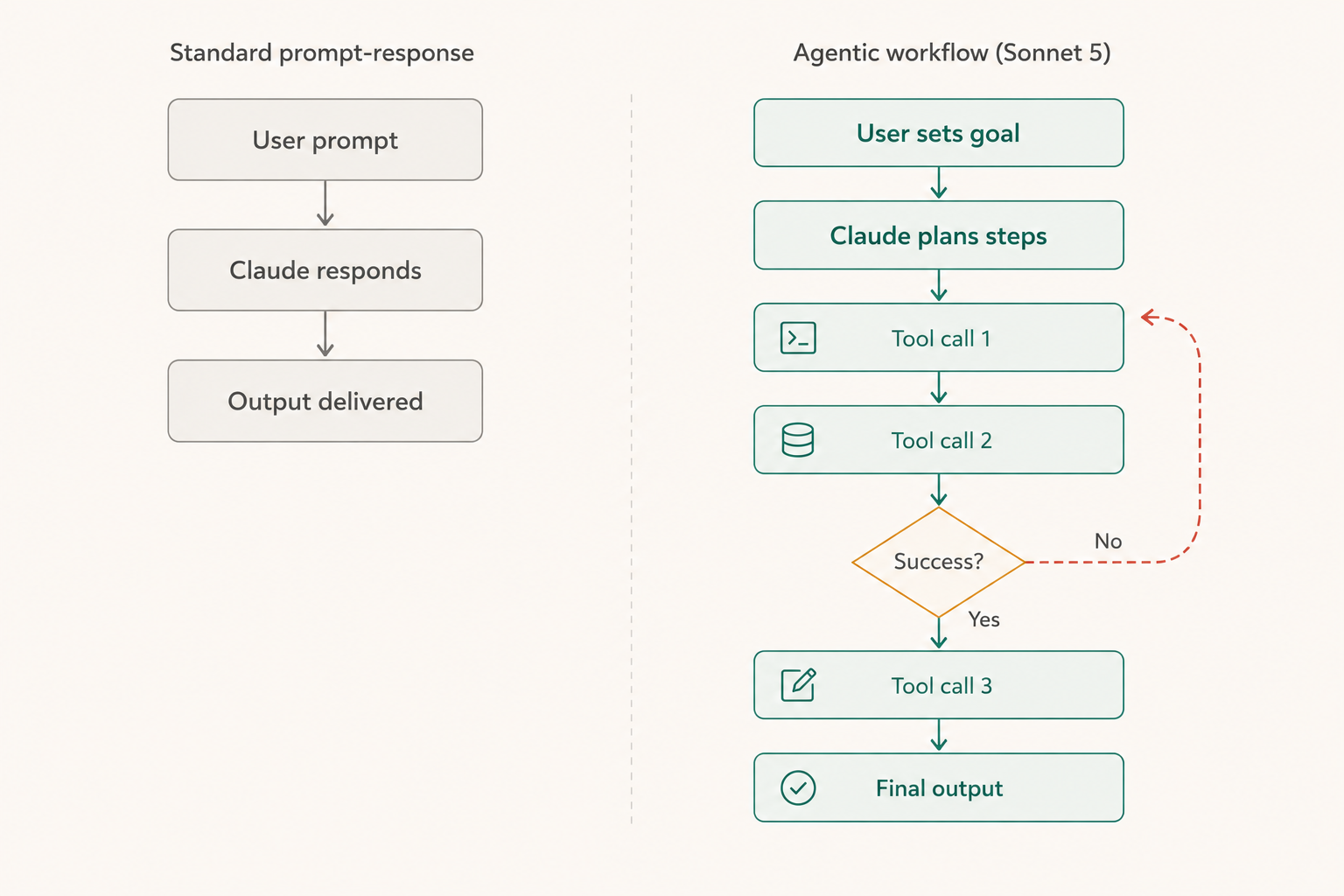
Expected upgrades in agentic capability
For agentic behavior to be reliable, you need a model that is good at task planning, tool selection, error recovery, and knowing when to ask for clarification rather than proceeding with a flawed assumption. These are exactly the areas where Anthropic's research has been pointed in recent years, particularly through their work on Constitutional AI, model alignment, and the kinds of careful, self-monitoring behavior that makes autonomous agents safe to deploy in consequential workflows.
Sonnet 5 is expected to improve at multi-step execution — the ability to carry a plan forward across ten, twenty, or fifty discrete actions without losing coherence. It should also improve at tool use, handling ambiguous situations, and recognizing when a task has gone off-track rather than confidently proceeding down a wrong path. That last quality — calibrated uncertainty — is arguably the single most important property for any agent you plan to run without close supervision.
Practical automation examples
What does better agentic behavior actually look like in use? A few grounded scenarios:
- Inbox triage: scanning emails, flagging what needs attention, drafting replies for approval, and setting follow-up reminders — all from a single instruction.
- Research assistance: pulling sources, extracting key findings, identifying contradictions across documents, and producing a structured summary without repeated prompting.
- Internal ops automation: running multi-step workflows across company tools — Notion, Jira, Slack, GitHub — with appropriate judgment about when to execute and when to surface decisions to humans.
- Scheduling: understanding context from prior conversations, proposing meeting times, checking availability, and sending calendar invites with relevant context pre-filled.
Claude Sonnet 5 will not solve every hard problem in agent reliability, that's an ongoing research frontier, but it is expected to raise the practical ceiling meaningfully from where Sonnet 4.5 sits today.
Pricing and model positioning
No matter how impressed people are by capability improvements, pricing is often the decisive factor in whether a model actually gets deployed. For teams running millions of API calls per month, the cost-per-token is not a footnote — it is a core operating expense. That makes the Sonnet tier's pricing trajectory one of the most closely watched aspects of any new release.
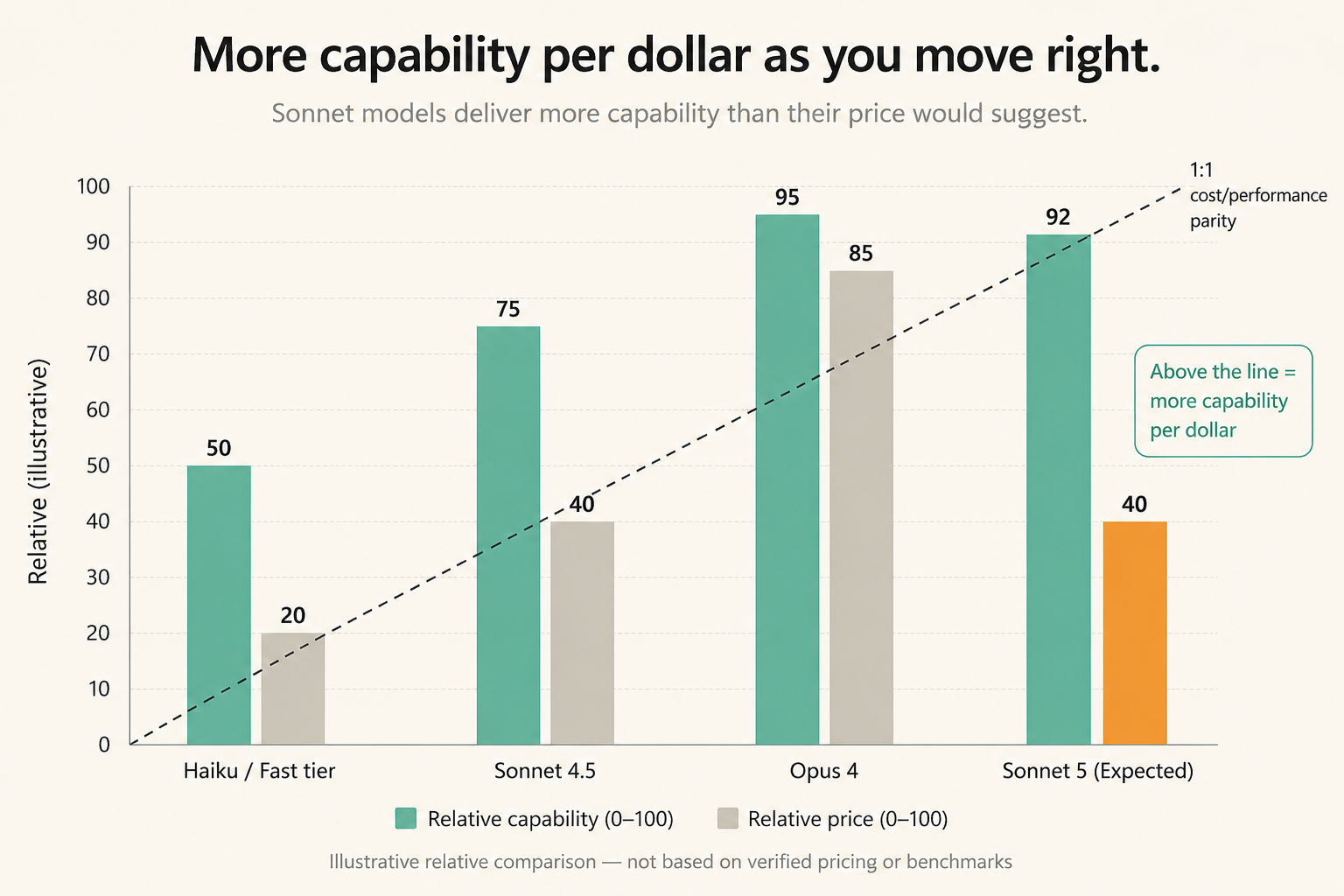
The cost-performance curve
The pattern across recent AI model generations has been consistent: each successive model at a given price tier delivers meaningfully more capability than the last. Sonnet 5 is expected to continue this trend. If it arrives near Opus-4-level performance at current Sonnet pricing — or cheaper — that is not just a marginal improvement. It potentially makes the economics of AI-heavy applications viable in cases where they currently are not.
For startups especially, this matters enormously. The difference between a model that costs $3 per million input tokens and one that costs $15 is the difference between a feature you can ship to all users and one you gate behind a premium tier. Sonnet 5's expected pricing efficiency could open up categories of product that are currently too expensive to build on frontier-quality intelligence.
Enterprise and API implications
For enterprise deployments, better cost-per-outcome — not just cost-per-token — is what matters. A model that completes a task in one turn costs less overall than a cheaper model that needs three attempts to get it right. Sonnet 5's expected improvements in instruction following and task completion quality should translate directly into lower effective costs for well-designed enterprise workflows, even if the nominal token pricing stays comparable to its predecessor.
Cost note
No official pricing has been confirmed for Claude Sonnet 5. Historical patterns suggest Sonnet models are positioned in Anthropic's mid-tier, below Opus pricing. Whether Sonnet 5 launches at, above, or below Sonnet 4.5's pricing will be one of the most closely watched details at announcement time.
What is still unknown
An honest expectations piece has to include a clear-eyed section on what we do not know. There is a meaningful difference between reasonable inference based on trajectory and confirmed fact, and collapsing that distinction does no one a favor.
What to watch when Sonnet 5 launches
When the announcement comes, the most useful signals to look for will be: the performance gap versus Sonnet 4.5 on coding benchmarks specifically (since that is where practical daily use is most measurable), the per-token pricing relative to Opus 4, the context window size and any claims about utilization quality, and early reports from developers using it in real agentic pipelines. Those four data points, more than any headline benchmark, will tell you what Sonnet 5 actually means for your work.
Start building with Claude today — Sonnet 5 ships to the same API from day one
When Claude Sonnet 5 launches, it will be available immediately through the AI/ML API. In the meantime, you have access to Claude Sonnet 4.6, the current best-in-class mid-tier model, plus 400+ other AI models across every major provider. One key, one endpoint, full coverage.
Full model library
GPT, Gemini, Mistral, Llama, DeepSeek, Grok, and hundreds more — all accessible from a single API key. Compare models in production without juggling vendor accounts. Browse all models →
Claude Sonnet 4.6
The current Sonnet-tier flagship — strong reasoning, fast responses, excellent instruction following, and the same model string Claude Sonnet 5 will eventually succeed. Try Sonnet 4.6 →
Try before you build
Test prompts across multiple models side by side in the browser — no setup, no credit card needed to start. When Sonnet 5 drops, it will appear here on day one. Open playground →



