
What Is Gemini Omni? Google's Any-to-Any Multimodal AI
From Prompt to Production: Inside Gemini Omni
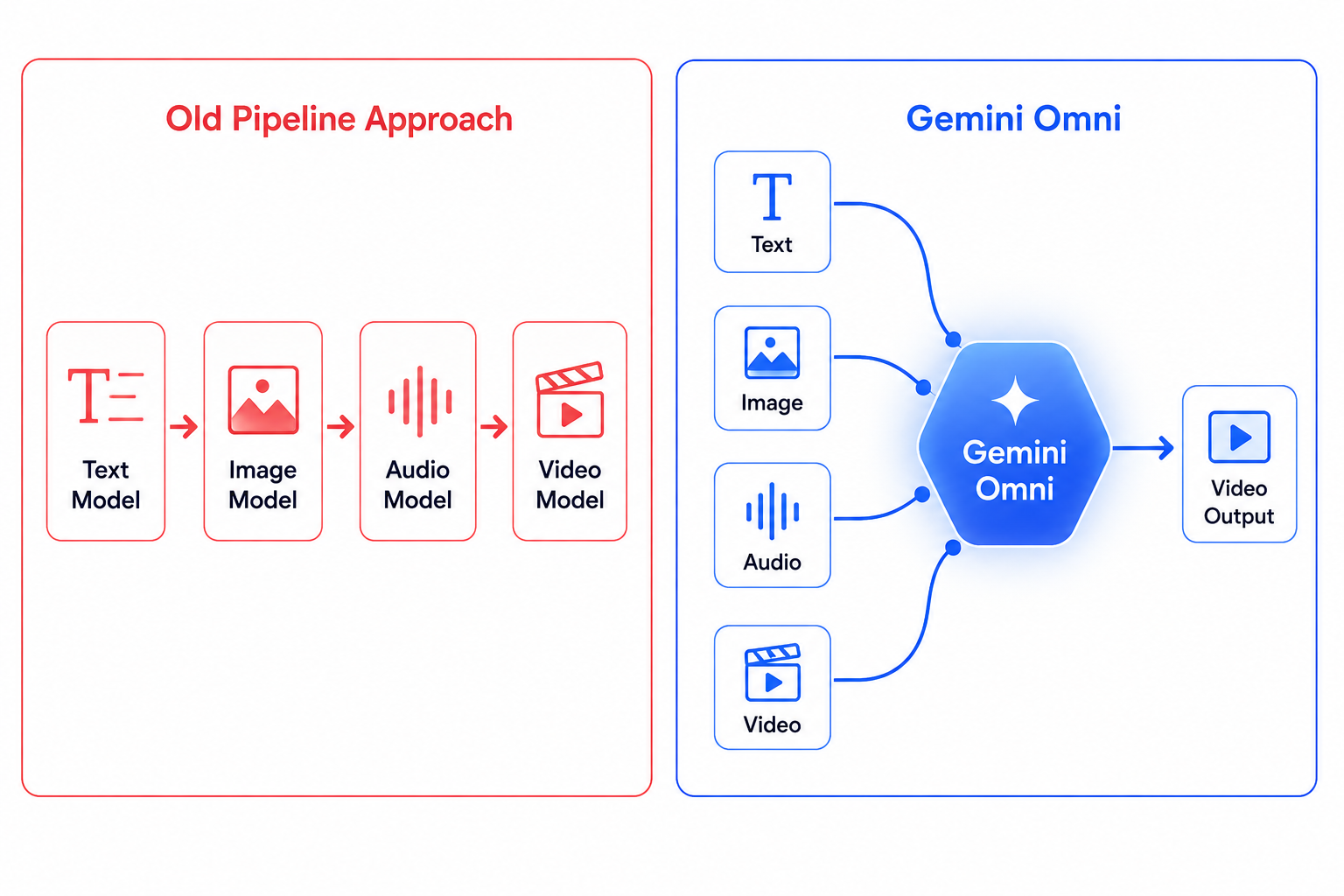
For a long time, the frontier of AI creativity moved in one direction: you typed something, and a model tried to turn words into a picture or a clip. That was impressive enough. But it was still a pipeline, a chain of disconnected tools each handling one job, passing their output down the line like a baton. Gemini Omni changes that architecture entirely.
Announced on May 19, 2026, alongside Google I/O, Gemini Omni is Google DeepMind's new native multimodal model built to accept virtually any combination of inputs — text, image, audio, and video — and generate high-quality video output, grounded in real-world reasoning. The first model in the Omni family, called Gemini Omni Flash, is already rolling out to Gemini app subscribers, Google Flow users, and YouTube Shorts creators.
For creators, it's a director, editor, and VFX artist rolled into one prompt. For marketers, it's a campaign studio that works at conversational speed. For developers, it's an API that understands physics, narrative, and style, not just pixels. And for anyone watching where AI is heading, Gemini Omni is one of the clearest signals yet that we're entering a genuinely different era of generative media.

What Is Gemini Omni?
Most AI models are specialists. Text-to-image models do text-to-image. Video generation tools take a prompt and produce footage. Audio models handle sound. In practice, getting them to work together means stitching outputs from one into inputs for another, which is slow, inconsistent, and hard to control. Gemini Omni is designed to replace that patchwork with a single system.
The name "Omni" is deliberate. Where earlier Gemini models focused on reasoning across modalities for understanding, Omni extends that native intelligence into generation. It's the point where Gemini's ability to reason about the world meets the ability to actually produce it, frame by frame.
The model sits inside the broader Google DeepMind model family — distinct from Veo (which focuses on cinematic video generation from text) and Nano Banana (which handles image creation and editing). Omni is explicitly positioned as the next evolution: Nano Banana for video, but deeper, because it reasons about motion, causality, and context in ways a still-image model doesn't need to.
How Gemini Omni Works
Three interlocking ideas explain how Gemini Omni actually operates and why each of them matters individually and together.
Any-to-Any Input and Output
Most current AI video tools take a text prompt, maybe with an image attached, and produce a short clip. Gemini Omni is more flexible than that at the input level. You can combine a voice recording, a reference image of a character, a video clip for motion style, and a written description — all at once — and the model synthesizes them into a single coherent output. Google describes this as "create anything from any input."
The key principle is one model, one interface. Rather than routing your reference image through one API and your video through another and hoping they talk to each other, Omni processes all those modalities together, natively, so they inform the output simultaneously instead of sequentially. At launch, the first model in the family outputs video; Google has indicated that image and audio outputs will follow as the Omni family expands.
Conversational Video Editing
This is probably the most immediately practical capability for most people. Traditional video editing tools require you to make a specific edit, render it, evaluate it, and then make another. There's no memory between operations. You're always starting from the file on disk.
Gemini Omni introduces context persistence across editing turns. Each instruction you give builds on the last. Ask it to "transport the violinist to a field environment," then "make the violin invisible," then "change the camera angle to over the shoulder" — and the model holds the thread across all three edits, keeping the character consistent, the environment coherent, and the scene logic intact. This edit-by-conversation workflow is closer to working with a human collaborator who remembers the context of the whole session than it is to operating a software tool.
Practically, this means you can refine a scene in natural language: change a lighting setup, swap a background, alter what happens at a specific moment, add sound effects tied to visual events, or transform a realistic clip into a stylized animation — all without leaving the conversation.
Physics Intuition and World Knowledge
One persistent problem with AI video generation has been that the outputs often look like they exist outside of reality — objects float, liquids behave like gel, gravity is optional. Gemini Omni addresses this in a specific way: it combines an intuitive model of physical forces (gravity, kinetic energy, fluid dynamics, inertia) with the broader world knowledge that Gemini has built up across history, science, mathematics, biology, and cultural context.
The practical result is that when you ask for a marble rolling on a chain-reaction track, it rolls like a marble. When you ask for a claymation explainer of protein folding, the model knows both how claymation moves and how protein folding actually works — and can render something that's visually accurate to both. Google frames this as bridging the gap between photorealism and meaningful storytelling: the model doesn't just make things look real, it makes things behave as if they understand the world they're in.
Key Features of Gemini Omni
Here's a structured breakdown of what Gemini Omni actually does, based on confirmed capabilities from Google DeepMind's official documentation and launch materials.
Gemini Omni Use Cases
The range of applications here is wide enough that "who is this for?" is almost the wrong question. The better question is: what kind of creative or production problem do you have that currently requires multiple tools, multiple steps, or multiple specialists?
Gemini Omni vs Other AI Video Models
Placing Gemini Omni in context against existing tools helps clarify what's actually new here — and where it fits in a workflow versus where it doesn't fully replace a more specialized approach.
Gemini Omni's differentiator is the combination of editing capability and generation capability within the same model, connected by persistent conversational context. Most competing tools do one or the other well. The "any-to-any" input flexibility is also genuinely unusual — most tools still have a primary input type, even if they accept a few others.
Building a multimodal pipeline now, before Gemini Omni's API releases? AI/ML API provides access to Gemini 3.5 Flash and 400+ other models through a single OpenAI-compatible endpoint.
Why Gemini Omni Matters for AI-Era Search
Beyond the technical capabilities, Gemini Omni sits at an interesting intersection of several converging search trends. Multimodal AI generation is one of the fastest-growing query categories right now, and Omni slots into multiple intent clusters simultaneously.
It captures branded informational intent (people trying to understand what the model is), comparison intent (how does it differ from Sora or Veo), tutorial intent (how do I use it to edit a video), and workflow automation intent (can I integrate it into a production pipeline via API). That's a rare combination of query types for a single product.
From a semantic perspective, the topic cluster around Gemini Omni connects naturally to: generative media models, natural language video editing, AI creative workflows, content provenance and watermarking, physics simulation in AI, and multimodal reasoning. Each of those is a growing area of search interest on its own — Omni just happens to sit at the center of all of them.
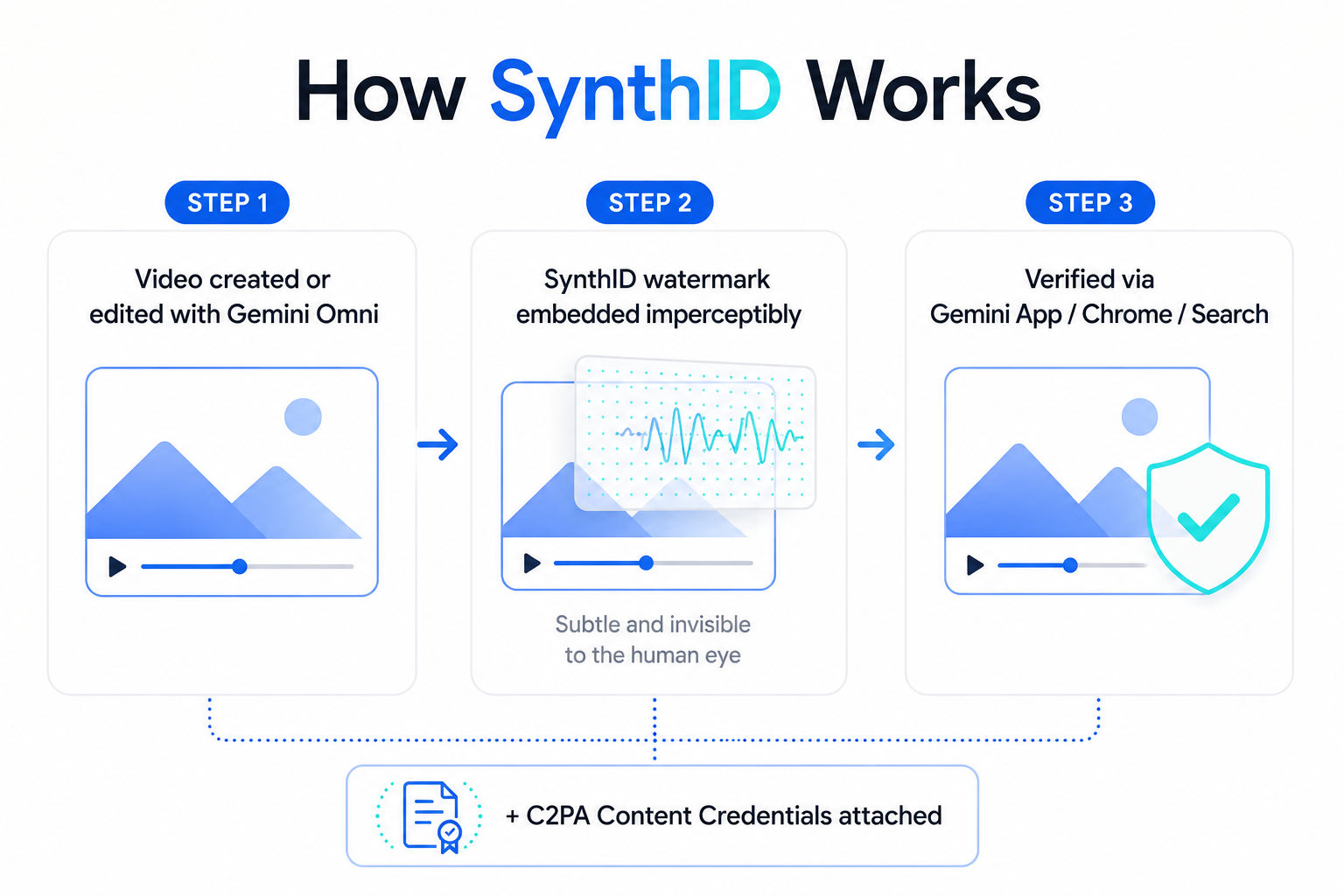
The SynthID and C2PA provenance angle also matters here. As AI-generated media becomes more common, tools for verifying the origin of video content are becoming a genuine search need. Omni's built-in watermarking positions it favorably in searches around AI media transparency and governance.
Frequently Asked Questions
What is Gemini Omni in simple terms?
Gemini Omni is Google DeepMind's AI model that can take any combination of text, images, audio, and video as input and produce video output. Unlike older tools that handle one modality at a time, Omni processes all inputs together — and lets you edit and refine results through natural conversation, with each instruction building on the last.
How does Gemini Omni differ from Veo?
Veo is primarily a text-to-video generation model — you give it a prompt and it creates cinematic footage from scratch. Gemini Omni goes further: it's a multimodal creation and editing system. It accepts mixed inputs (images, audio, existing video, text simultaneously), and crucially lets you edit videos conversationally across multiple turns with persistent context. Think of Veo as focused on creation, and Omni as focused on creation plus editing plus input flexibility.
Can Gemini Omni edit existing video?
Yes — this is one of its core capabilities. You can upload an existing video and edit it through natural language: change the background environment, transform the style, alter what's happening in the scene, change the camera angle, add sound effects tied to visual events, or swap characters and objects. Each edit maintains consistency with previous edits in the same conversation session.
What is SynthID and why does Gemini Omni use it?
SynthID is Google DeepMind's imperceptible digital watermarking technology. Every video generated or edited with Gemini Omni automatically receives a SynthID watermark — embedded in a way that isn't visible to the human eye but can be detected by verification tools. Omni also adds C2PA Content Credentials, an open standard for media provenance. You can verify Omni-generated content via the Gemini app, Gemini in Chrome, and Google Search.



