Whether you’re building real-time coding assistants, enterprise-grade document analyzers, or multilingual applications, Gemma 4 31B provides reliable, high-quality output with fast inference, unified billing, and high rate limits.
Google DeepMind's Gemma 4 31B is the most capable open-weight model in its class, delivering frontier-level reasoning, native multimodal understanding, and a 256K-token context window under a fully commercial Apache 2.0 license.
What is Gemma 4 31B?
Gemma 4 is Google DeepMind's fourth-generation open model family, built on the same research foundation that powers Gemini 3. The 31B variant is the flagship dense model in the lineup: all 31 billion parameters activate on every token, giving you consistent, high-quality output with no sparsity tradeoffs.
On the LMArena text leaderboard, the 31B model scores 1452, competitive with models many times its size. For development teams that care about the cost-per-quality tradeoff, this is one of the most efficient paths to frontier-class performance available today.
Model specs at a glance
Model name
Gemma 4 31B
Architecture
Dense transformer
Parameters
31B (fully dense)
Context window
256,000 tokens
Input modalities
Text · Images (variable res.) · Video (up to 60s @ 1fps)
Output
Text
Attention mechanism
Hybrid sliding-window + global full-context
Multilingual
35+ natively, pre-trained on 140+
Function calling
Native (structured tool use)
Thinking mode
Configurable via <|think|> token
Training data cutoff
January 2025
License
Apache 2.0 — commercial OK
Gemma 4 API Pricing:
Input: $0.5486 / 1M tokens
Output: $0.5486 / 1M tokens
What powers the performance
Gemma 4 31B uses a hybrid attention design that alternates between local sliding-window layers and global full-context layers, the final layer is always global. This combination means the model retains the low-memory characteristics of lightweight attention for most tokens while still building deep cross-document awareness where it counts. It's what makes the 256K context window practically usable rather than just theoretically possible.
Global attention layers apply Proportional RoPE (p-RoPE) and unified Keys and Values to keep memory consumption manageable on long inputs. Per-Layer Embeddings (PLE) give each decoder layer its own token-specific signal, a lightweight residual that lets the model specialize layer-by-layer without ballooning the parameter count. Shared KV caching at the tail layers eliminates redundant projections, reducing both memory pressure and latency for long-context generation.
Hybrid attention
Alternating local and global layers keep memory low while retaining deep contextual awareness across very long inputs.
Per-Layer Embeddings
Each decoder layer receives its own token-specific residual signal for deeper specialization at minimal extra cost.
Shared KV cache
Tail layers reuse key-value states, cutting memory and compute overhead on long-context generation without hurting quality.
Proportional RoPE
p-RoPE handles position encoding in global attention layers, enabling accurate retrieval across the full 256K context.
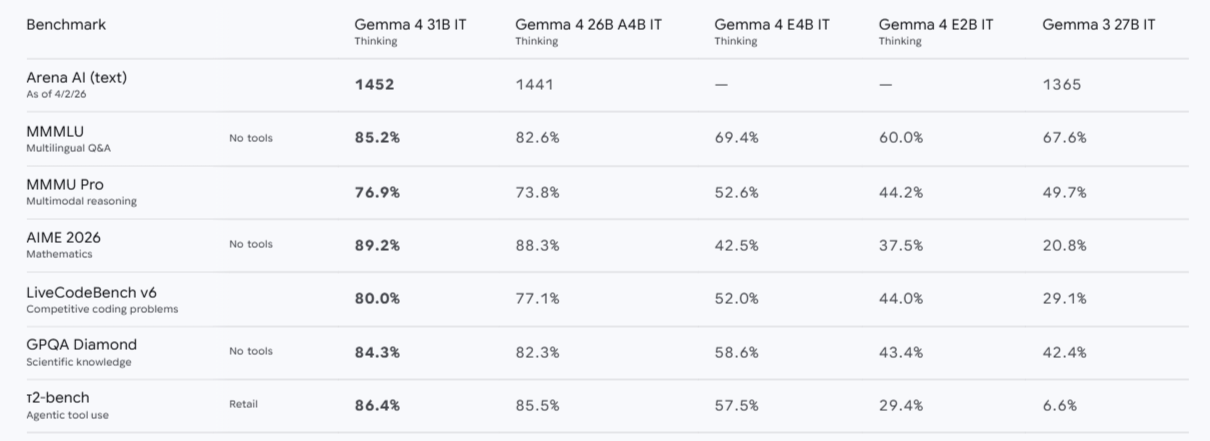
Gemma 4 31B Benchmark Results
Benchmarks don't tell the whole story, but they do give a useful reference point. The 31B dense model consistently competes with much larger closed-source models on reasoning and coding — particularly impressive given its fully open licensing and inference efficiency.
Benchmarks show relative performance within the Gemma 4 family and general competitive range. LMArena score is the estimated text-only score reported at launch.
Performance Architecture: Why It’s Fast and Efficient
Gemma 4 31B combines hybrid attention, per-layer embeddings, and shared KV caching for efficiency on long inputs:
Feature
Benefit
Hybrid attention
Alternates between sliding-window local layers and global full-context layers, keeping memory low while maintaining deep context awareness.
Per-Layer Embeddings (PLE)
Each decoder layer receives its own token-specific residual signal, enhancing layer specialization with minimal extra cost.
Shared KV cache
Tail layers reuse key-value states, reducing compute and memory overhead for long-context generation.
Proportional RoPE (p-RoPE)
Accurate position encoding across the full 256K context without excessive memory use.
What Developers Are Building With Gemma 4 31B
The combination of a 256K context window, native function calling, and multimodal input opens up a wide range of production use cases, from document-heavy enterprise tools to real-time coding assistants to multilingual consumer apps.
Agentic Workflows and Tool Use
Gemma 4 31B supports native function calling and structured JSON output. You can define tools in the standard format and the model handles multi-step planning, tool invocation, and result interpretation. It can also output bounding boxes, making it unusually capable for browser automation, UI element detection, and screen-parsing agents.
Long-Document Understanding
At 256K tokens, you can feed the model an entire codebase, a full legal contract stack, a multi-year financial report, or a lengthy product specification, and ask coherent questions across the full body of text. The hybrid attention mechanism keeps this practical rather than just theoretical.
Multimodal Document Processing
Gemma 4 31B processes images at variable resolution and aspect ratio. This makes it well-suited for OCR pipelines, form data extraction, invoice parsing, and any workflow where the model needs to read visual documents rather than just text files. Video input up to 60 seconds at 1 fps extends this to recorded demos, walkthroughs, and surveillance analysis.
Multilingual Applications
Pre-trained on 140+ languages with native support for 35+, Gemma 4 31B handles multilingual customer support, content localization, cross-language document summarization, and translation workflows without requiring separate language-specific fine-tunes.
Code Generation and Review
Google's training mix included substantial code data. The model handles code generation, completion, debugging, and review well and the configurable extended thinking mode (triggered via the <|think|> token) gives it space to reason through complex logic before producing output.
Gemma 4 31B vs. the 26B MoE — Which Should You Use?
Gemma 4 ships in two workstation-class sizes. The 31B is a dense model; the 26B A4B is a Mixture-of-Experts (MoE) architecture with only 4B parameters active per token. Here's how to think about the choice:
Gemma 4 is Google DeepMind's fourth-generation open model family, built on the same research foundation that powers Gemini 3. The 31B variant is the flagship dense model in the lineup: all 31 billion parameters activate on every token, giving you consistent, high-quality output with no sparsity tradeoffs.
On the LMArena text leaderboard, the 31B model scores 1452, competitive with models many times its size. For development teams that care about the cost-per-quality tradeoff, this is one of the most efficient paths to frontier-class performance available today.
Model specs at a glance
Model name
Gemma 4 31B
Architecture
Dense transformer
Parameters
31B (fully dense)
Context window
256,000 tokens
Input modalities
Text · Images (variable res.) · Video (up to 60s @ 1fps)
Output
Text
Attention mechanism
Hybrid sliding-window + global full-context
Multilingual
35+ natively, pre-trained on 140+
Function calling
Native (structured tool use)
Thinking mode
Configurable via <|think|> token
Training data cutoff
January 2025
License
Apache 2.0 — commercial OK
Gemma 4 API Pricing:
Input: $0.5486 / 1M tokens
Output: $0.5486 / 1M tokens
What powers the performance
Gemma 4 31B uses a hybrid attention design that alternates between local sliding-window layers and global full-context layers, the final layer is always global. This combination means the model retains the low-memory characteristics of lightweight attention for most tokens while still building deep cross-document awareness where it counts. It's what makes the 256K context window practically usable rather than just theoretically possible.
Global attention layers apply Proportional RoPE (p-RoPE) and unified Keys and Values to keep memory consumption manageable on long inputs. Per-Layer Embeddings (PLE) give each decoder layer its own token-specific signal, a lightweight residual that lets the model specialize layer-by-layer without ballooning the parameter count. Shared KV caching at the tail layers eliminates redundant projections, reducing both memory pressure and latency for long-context generation.
Hybrid attention
Alternating local and global layers keep memory low while retaining deep contextual awareness across very long inputs.
Per-Layer Embeddings
Each decoder layer receives its own token-specific residual signal for deeper specialization at minimal extra cost.
Shared KV cache
Tail layers reuse key-value states, cutting memory and compute overhead on long-context generation without hurting quality.
Proportional RoPE
p-RoPE handles position encoding in global attention layers, enabling accurate retrieval across the full 256K context.
Gemma 4 31B Benchmark Results
Benchmarks don't tell the whole story, but they do give a useful reference point. The 31B dense model consistently competes with much larger closed-source models on reasoning and coding — particularly impressive given its fully open licensing and inference efficiency.
Benchmarks show relative performance within the Gemma 4 family and general competitive range. LMArena score is the estimated text-only score reported at launch.
Performance Architecture: Why It’s Fast and Efficient
Gemma 4 31B combines hybrid attention, per-layer embeddings, and shared KV caching for efficiency on long inputs:
Feature
Benefit
Hybrid attention
Alternates between sliding-window local layers and global full-context layers, keeping memory low while maintaining deep context awareness.
Per-Layer Embeddings (PLE)
Each decoder layer receives its own token-specific residual signal, enhancing layer specialization with minimal extra cost.
Shared KV cache
Tail layers reuse key-value states, reducing compute and memory overhead for long-context generation.
Proportional RoPE (p-RoPE)
Accurate position encoding across the full 256K context without excessive memory use.
What Developers Are Building With Gemma 4 31B
The combination of a 256K context window, native function calling, and multimodal input opens up a wide range of production use cases, from document-heavy enterprise tools to real-time coding assistants to multilingual consumer apps.
Agentic Workflows and Tool Use
Gemma 4 31B supports native function calling and structured JSON output. You can define tools in the standard format and the model handles multi-step planning, tool invocation, and result interpretation. It can also output bounding boxes, making it unusually capable for browser automation, UI element detection, and screen-parsing agents.
Long-Document Understanding
At 256K tokens, you can feed the model an entire codebase, a full legal contract stack, a multi-year financial report, or a lengthy product specification, and ask coherent questions across the full body of text. The hybrid attention mechanism keeps this practical rather than just theoretical.
Multimodal Document Processing
Gemma 4 31B processes images at variable resolution and aspect ratio. This makes it well-suited for OCR pipelines, form data extraction, invoice parsing, and any workflow where the model needs to read visual documents rather than just text files. Video input up to 60 seconds at 1 fps extends this to recorded demos, walkthroughs, and surveillance analysis.
Multilingual Applications
Pre-trained on 140+ languages with native support for 35+, Gemma 4 31B handles multilingual customer support, content localization, cross-language document summarization, and translation workflows without requiring separate language-specific fine-tunes.
Code Generation and Review
Google's training mix included substantial code data. The model handles code generation, completion, debugging, and review well and the configurable extended thinking mode (triggered via the <|think|> token) gives it space to reason through complex logic before producing output.
Gemma 4 31B vs. the 26B MoE — Which Should You Use?
Gemma 4 ships in two workstation-class sizes. The 31B is a dense model; the 26B A4B is a Mixture-of-Experts (MoE) architecture with only 4B parameters active per token. Here's how to think about the choice:





-min-p-130x130q80.png)
.webp)

