
Voice
Active
Inworld TTS-1
A next-generation neural text-to-speech (TTS) model developed by Inworld AI, engineered specifically for dynamic, real-time conversational experiences within games, virtual agents, and immersive applications.


TTS-1 is optimized for context-aware emotional expression, low-latency inference, and natural prosody, delivering voice that feels human, responsive, and situationally appropriate.
Inworld TTS-1 is a state-of-the-art Transformer-based autoregressive text-to-speech (TTS) model designed for high-quality, real-time speech synthesis across multiple languages. It offers low latency audio generation at high resolution (48 kHz), supports fine-grained emotional control, and is optimized for both on-device and cloud applications.
The model outperforms many competitive models in terms of multilingual speech quality, emotional control, and latency.
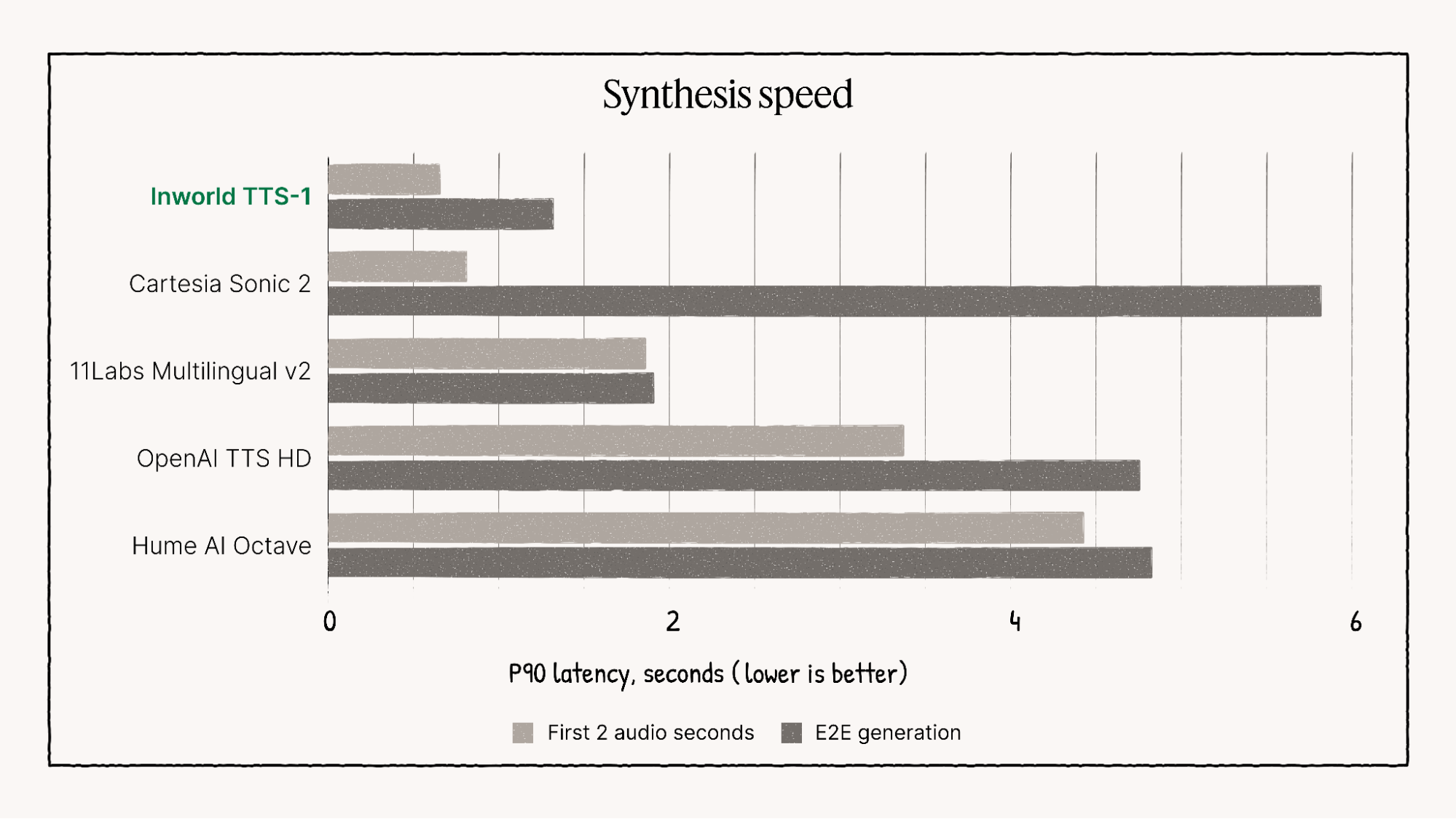
vs Google WaveNet: Inworld TTS-1 offers lower latency and better real-time synthesis capabilities, making it ideal for interactive applications, whereas WaveNet provides highly natural and expressive speech but with higher computational cost.
vs 11LABS Multilingual V2: Inworld TTS-1 provides finer emotional nuance and lower latency for live interaction use cases, whereas 11LABS offers strong multilingual capabilities with a simpler interface. 11LABS is favored for ease of use, while Inworld TTS-1 is preferred for premium, expressive output.
vs OpenAI TTS-1-HD: OpenAI TTS-1-HD produces ultra-high-definition audio with studio-quality fidelity, surpassing Inworld in audio richness but at the expense of higher latency and cost. Inworld TTS-1 is more cost-efficient and versatile for multilingual and device-flexible deployments, making it suited for everyday real-time needs.
Inworld TTS-1 is a state-of-the-art Transformer-based autoregressive text-to-speech (TTS) model designed for high-quality, real-time speech synthesis across multiple languages. It offers low latency audio generation at high resolution (48 kHz), supports fine-grained emotional control, and is optimized for both on-device and cloud applications.
The model outperforms many competitive models in terms of multilingual speech quality, emotional control, and latency.
vs Google WaveNet: Inworld TTS-1 offers lower latency and better real-time synthesis capabilities, making it ideal for interactive applications, whereas WaveNet provides highly natural and expressive speech but with higher computational cost.
vs 11LABS Multilingual V2: Inworld TTS-1 provides finer emotional nuance and lower latency for live interaction use cases, whereas 11LABS offers strong multilingual capabilities with a simpler interface. 11LABS is favored for ease of use, while Inworld TTS-1 is preferred for premium, expressive output.
vs OpenAI TTS-1-HD: OpenAI TTS-1-HD produces ultra-high-definition audio with studio-quality fidelity, surpassing Inworld in audio richness but at the expense of higher latency and cost. Inworld TTS-1 is more cost-efficient and versatile for multilingual and device-flexible deployments, making it suited for everyday real-time needs.



-min-p-130x130q80.png)
.webp)

