
Video
Active
Wan 2.1 Turbo
It offers rapid inference speed, strong vision-language fusion, and multi-step reasoning, making it ideal for real-time and cost-effective multimedia applications.

.webp)
Wan2.1-T2V-Turbo is efficient text-to-video AI model designed for fast, high-quality video generation from textual input.
Alibaba's Wan2.1 Turbo is a cutting-edge text-to-video AI model optimized for efficient generation with balanced performance and speed. It processes large context inputs and excels in generating high-quality videos with smooth temporal dynamics and rich semantic alignment between text and visuals.
Wan2.1 Turbo achieves excellent video generation quality while significantly reducing inference time and compute compared to larger models, making it well-suited for real-time or cost-sensitive applications. It retains Alibaba’s hallmark capability in dynamic motion, spatial relationships, and compositional accuracy.
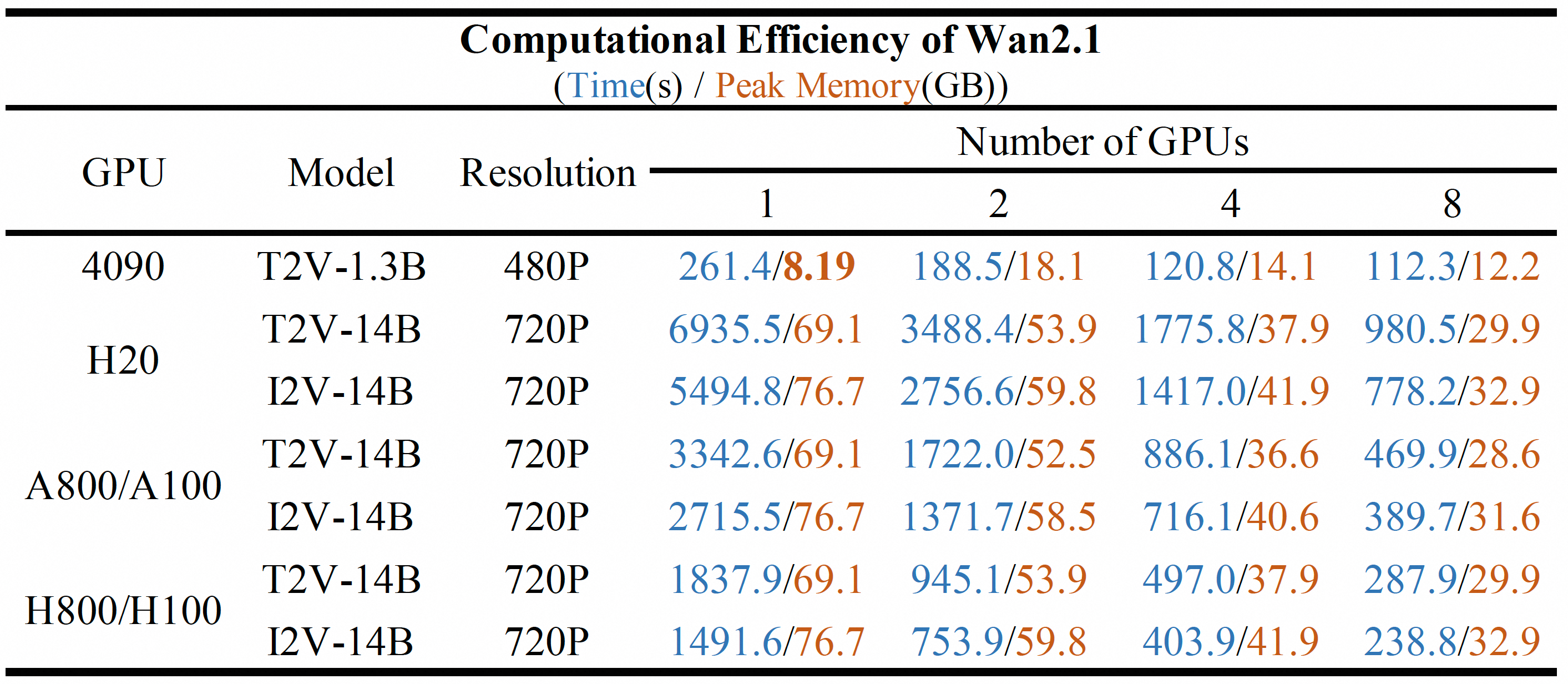
Vs. Wan2.2-T2V: Slightly lower maximum generation resolution and model size, but offers much faster inference and cost efficiency.
Vs. Gemini 2.5 Flash: Competitive multi-modal accuracy optimized for speed.
Vs. OpenAI GPT-4 Vision: Smaller context window but more cost-effective for video generation tasks.
Vs. Qwen3-235B-A22B: Focused on turbo efficiency with slightly lower retrieval precision.
Some generation outputs may occasionally include minor artifacts or less detailed textures compared to the largest Wan2.2 models; however, these can often be minimized via prompt engineering or post-processing.
Alibaba's Wan2.1 Turbo is a cutting-edge text-to-video AI model optimized for efficient generation with balanced performance and speed. It processes large context inputs and excels in generating high-quality videos with smooth temporal dynamics and rich semantic alignment between text and visuals.
Wan2.1 Turbo achieves excellent video generation quality while significantly reducing inference time and compute compared to larger models, making it well-suited for real-time or cost-sensitive applications. It retains Alibaba’s hallmark capability in dynamic motion, spatial relationships, and compositional accuracy.
Vs. Wan2.2-T2V: Slightly lower maximum generation resolution and model size, but offers much faster inference and cost efficiency.
Vs. Gemini 2.5 Flash: Competitive multi-modal accuracy optimized for speed.
Vs. OpenAI GPT-4 Vision: Smaller context window but more cost-effective for video generation tasks.
Vs. Qwen3-235B-A22B: Focused on turbo efficiency with slightly lower retrieval precision.
Some generation outputs may occasionally include minor artifacts or less detailed textures compared to the largest Wan2.2 models; however, these can often be minimized via prompt engineering or post-processing.







.webp)



