
DeepSeek vs ChatGPT in 2026: The Complete Model Breakdown
How They're Built and Why It Actually Matters
The choices DeepSeek and OpenAI made at the engineering level directly determine cost, speed, customisation potential, and where each model struggles.
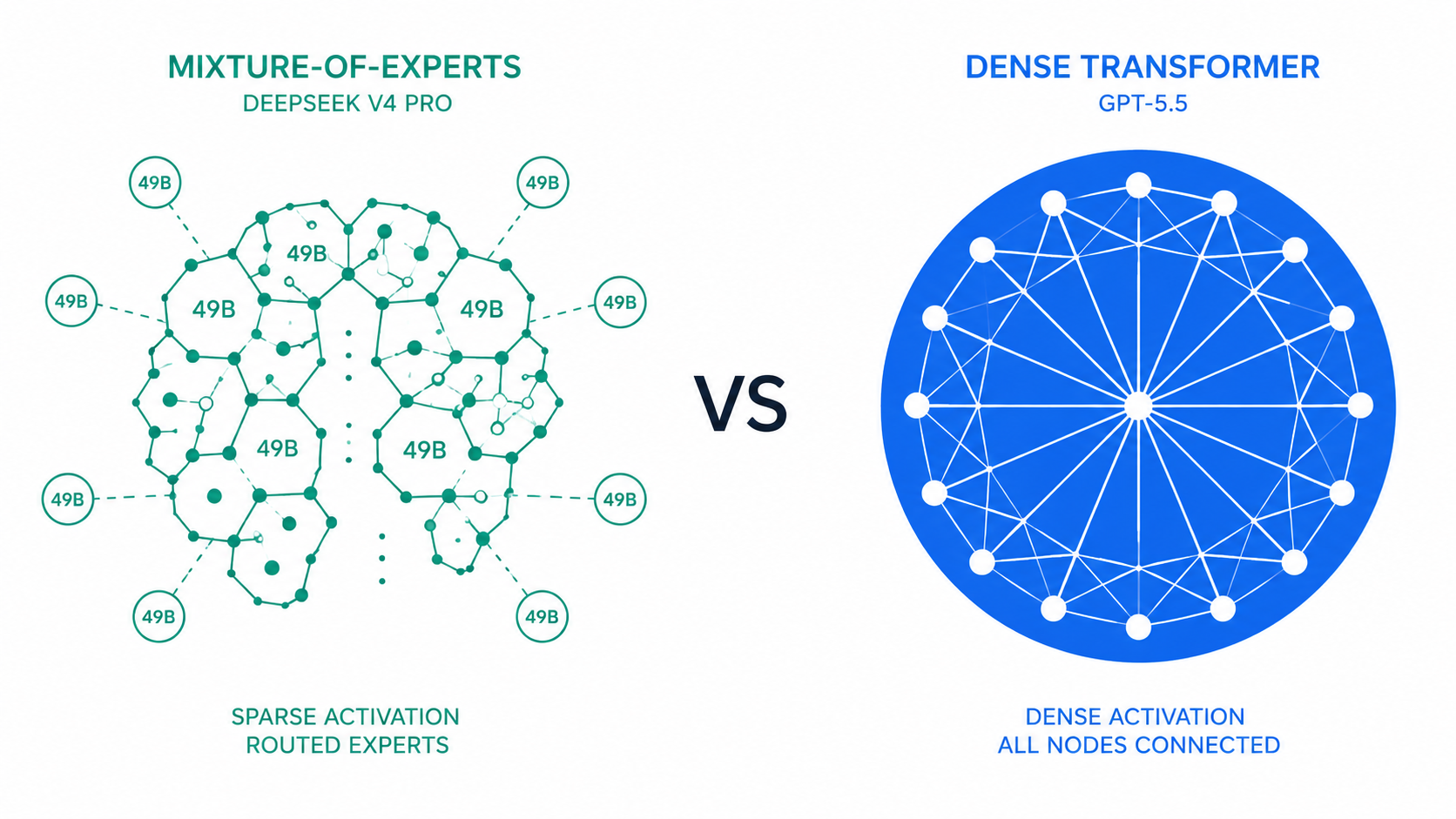
DeepSeek: Mixture-of-Experts
DeepSeek's architecture is built around a Mixture-of-Experts (MoE) approach. Rather than activating every parameter for every query, the model routes each token through a small subset of specialised "expert" subnetworks. V4 Pro has 1.6 trillion parameters total but only activates 49 billion per token, meaning you get near-frontier output without near-frontier compute costs.
This isn't a shortcut. It's a deliberate architectural choice that enabled DeepSeek to train V3's predecessor in 55 days on 2,048 Nvidia H800 GPUs at a total cost of roughly $5.5 million — a fraction of what frontier closed models require. The savings pass directly to users through dramatically lower API prices.
The R1 and V3/V4 lines also incorporate reinforcement learning post-training, which sharpens step-by-step logical reasoning. This is the mechanism behind DeepSeek's "think out loud" capability, it doesn't just give you an answer, it walks through the reasoning, which is unusually valuable for verification in technical work.
- Lower inference cost via dynamic expert activation
- Open weights: download, fine-tune, self-host
- Strong transparent chain-of-thought reasoning
- Trained on 14.8T tokens with Multi-Head Latent Attention
OpenAI: Dense transformers → full retrain
ChatGPT's GPT family historically relied on dense transformer architecture, activating all parameters on every forward pass. That approach gives extraordinary breadth and versatility — every neuron has a chance to contribute to every output, but it's computationally expensive and resource-intensive to run at scale.
GPT-5.5 marks a turning point. Unlike the incremental GPT-5.1 through 5.4 updates that all ran on the same architectural foundation, GPT-5.5 is described by OpenAI as a full ground-up retrain. The specific focus was agentic reliability — ensuring the model can plan across dozens of tool calls, recover from dead ends, and sustain coherence over long-running tasks without human intervention at each step.
OpenAI's GPT-5.5 also supports five levels of reasoning effort — from "none" for instant responses to "xhigh" for the deepest analysis, allowing developers to trade latency against quality per request.
- Full multimodal: text, image, audio, video in one context
- Five reasoning-effort tiers (none → xhigh)
- Extensive ecosystem: Canvas, Codex, Atlas browser, voice mode
- GPT-5.5: first full architectural retrain since GPT-4.5
Architecture takeaway
DeepSeek's MoE design makes it structurally cheaper to run and easier to self-host, that's a permanent advantage, not just a pricing promotion. OpenAI's dense + retrain approach produces a model with broader capability coverage and superior agentic coherence at the cost of significantly higher API pricing and no open weights. These aren't equivalent trade-offs, they serve genuinely different use cases.
Benchmark Results: Math, Coding, and Reasoning
Benchmark results tell you where a model is genuinely strong, not where marketing says it is. The important nuance: neither family wins everything, and the gaps between reasoning and non-reasoning modes often exceed the gaps between brands.

What the numbers actually mean
A few things worth unpacking before you weight these scores too heavily. First, DeepSeek V4 Pro was launched in late April 2026 with explicit acknowledgment that it trails state-of-the-art frontier models on knowledge benchmarks by "approximately 3 to 6 months." That's an honest self-assessment, not a damning verdict — especially when V4 Pro undercuts GPT-5.5 on price by an order of magnitude.
Second, the math benchmark comparison above mixes different generations of models. DeepSeek R1's ~90% on advanced math tests came from a different benchmark window than GPT-5.5's FrontierMath scores. The direct head-to-head across the same suite at the same time shows GPT-5.5 with an edge in the hardest tier, DeepSeek competitive in the mid tiers.
Third, and most importantly: the gap between a non-reasoning model and a reasoning model is typically larger than the gap between DeepSeek and OpenAI within the same tier. If you're using GPT-5.4 Mini without enabling thinking mode, you're leaving performance on the table that far exceeds any brand difference.
- DeepSeek benchmark strength: Logic-heavy structured tasks, explicit step-by-step reasoning (chain-of-thought transparency), math at the mid tier, and coding accuracy per dollar. The open-source community has also documented strong performance on scientific derivations and proofs, areas where showing the work matters as much as reaching the right answer.
- OpenAI benchmark strength: Long-horizon agentic coding (Expert-SWE), terminal and tooling tasks (Terminal-Bench 2.0), hardest math tier (FrontierMath level 4), and overall multi-domain consistency. GPT-5.5's ground-up retrain specifically targeted the failure modes that hurt earlier models on complex agent tasks.
Real-World Task Testing: Where Each Model Pulls Ahead
Benchmark percentages don't tell you how a model feels to work with. Here's how the two families actually perform across the task types that appear in daily work — content, code, academic explanation, and data analysis.
Content creation and writing
When generating structured written content — articles, outlines, reports, product descriptions — the two families show a meaningful stylistic divergence. DeepSeek tends to reason through structure before writing, often laying out its approach before producing the final output. This is valuable when you want explainability or when you're debugging why an outline is wrong. The output tends to be logically organised and precise, leaning technical.
ChatGPT (particularly GPT-5.5 and GPT-5.4) produces cleaner, more immediately polished prose for general audiences. It handles tonal variation better — shifting from formal to conversational without explicit prompting — and its outputs feel more like finished copy from the first draft. This comes from OpenAI's much larger investment in RLHF (Reinforcement Learning from Human Feedback) on conversational quality specifically.
- Content writing: ChatGPT for audience-facing copy, nuanced tone matching, and creative work. DeepSeek for technical documentation, structured outlines, and high-volume generation where cost matters.
Coding and software development
For algorithm-heavy work, mathematical problem-solving embedded in code, and tasks where you want to see the reasoning behind a solution, DeepSeek V4 Pro and the R1-series are genuinely excellent. The chain-of-thought transparency means you can spot where the model's logic diverges from yours, which is valuable in debugging and code review contexts.
For large codebase work — navigating a real repository, understanding dependencies across dozens of files, running automated refactors, or pushing commits — GPT-5.3-Codex is in a different category. It was purpose-built for this workflow, with repo search, terminal execution, and the ability to search across an entire codebase before answering. GPT-5.5 extends this with better multi-step task completion for agentic coding runs that might take 20+ minutes of autonomous execution.
For everyday code generation — writing a utility function, debugging a specific error, translating between languages — both families perform well. The practical difference comes down to whether you're willing to self-host for cost savings (DeepSeek) or whether you need the integrated tooling around the model (OpenAI Codex environment).
- Coding: GPT-5.3-Codex and GPT-5.5 for large codebase work and autonomous agent runs. DeepSeek V4 Pro for logic-heavy algorithmic work, step-by-step transparency, and high-volume API usage where per-token cost matters.
Academic and educational use
DeepSeek's chain-of-thought approach gives it a natural advantage in academic contexts, particularly STEM subjects where showing the method is as important as reaching the answer. Physics derivations, mathematical proofs, algorithm analysis: DeepSeek walks through each step, identifies where conversions are needed, and flags assumptions. For researchers who need to verify each stage of a solution, that transparency is genuinely useful.
ChatGPT tends to produce more complete educational explanations that are better suited for learning rather than verification. Ask it a physics problem and it will explain what each variable represents, walk through the calculation, and then recap the result in accessible language. That's significantly better for students who need to understand the concept, not just check their answer.
Multimodal tasks: image, audio, video
This is currently a one-sided comparison. DeepSeek V4 (both Flash and Pro) supports text only. DeepSeek V3.2 and V3.1 support text and images, but not audio or video. OpenAI's GPT-5.5 handles all four modalities natively — you can paste an image, attach an audio clip, and provide a video reference all in the same conversation, and the model reasons across all of them simultaneously.
For any workflow involving visual content — UI review, document parsing, chart analysis, visual debugging, video summarisation, voice interaction, you currently need to be in the OpenAI stack. GPT-5.5's multimodal breadth is one of its most distinctive advantages and something DeepSeek has explicitly not prioritised in the V4 generation.
- Multimodal: GPT-5.5 has no competition from DeepSeek in this category. If your workflow involves anything beyond text and static images, GPT-5.x is the only viable option between these two families.
Feature Comparison: Ecosystem, Memory, and Integrations
Raw model capability is only part of the picture. The product built around the model — its memory, integrations, interface, and tooling ecosystem — often determines which choice makes sense for a team.
The feature gap tells a clear story: OpenAI has spent years building a product ecosystem around its models. ChatGPT is not just a model — it's a full workspace. DeepSeek's strength is the opposite: it's closer to the model layer, giving developers maximum control and minimum overhead, but at the cost of a polished end-user experience.
Who Should Use What — A Practical Guide
The honest answer to "which is better" is almost always "it depends on the task." Here's a framework for making that decision consistently, without debating it fresh each time.
The "use both" strategy
Many high-performing teams in 2026 don't pick a side at all. The emerging pattern is a task-routing layer that sends logic-heavy and high-volume requests to DeepSeek (V4 Flash or V3.2 for cost, V4 Pro for quality) while routing multimodal, creative, and agentic tasks to GPT-5.4 or GPT-5.5. Managed through a unified API endpoint on AI/ML API, this approach gives you the best of both families without duplicating infrastructure or billing relationships.
The key is recognising that DeepSeek and ChatGPT occupy different layers of the stack. DeepSeek is primarily a model — powerful, open, and cheap to run. ChatGPT is a product environment — polished, featureful, and designed for teams who want a finished tool rather than raw model access. Those aren't the same thing, and comparing them as if they are misses the real decision.
Common questions
Is DeepSeek V4 better than ChatGPT in 2026?
It depends on the task. On coding competition benchmarks, DeepSeek V4 Pro is roughly comparable to GPT-5.4. On long-horizon agentic work and multimodal tasks, GPT-5.5 still leads. DeepSeek wins clearly on price and open-weight accessibility.
What is DeepSeek V3.2 and should I still use it?
DeepSeek V3.2 (671B parameters, 128K context) is the proven mid-tier option. It's cheaper than V4, handles multimodal inputs including images, and is a solid default for most text and code tasks that don't require a 1M context window or the most advanced reasoning.
What's the difference between GPT-5.3, 5.4, and 5.5?
GPT-5.3-Codex (Feb 2026) is a code specialist that searches repos and runs terminal commands. GPT-5.4 (Mar 2026) is the first mainline reasoning model to incorporate 5.3's frontier coding capabilities, with significantly better token efficiency than 5.2. GPT-5.5 (Apr 2026) is a ground-up retrain focused on agentic reliability, long-context coherence, and multi-modal breadth.
Can DeepSeek understand images and audio?
Partially. DeepSeek V3.2 and V3.1 support text and image inputs. DeepSeek V4 (both Flash and Pro) is text-only in the current release. Neither supports audio or video input. OpenAI's GPT-5.5 supports all four modalities — text, images, audio, and video — natively within the same conversation. If your workflow involves anything beyond text and static images, GPT-5.x is currently the only option within this comparison.



