
Kimi K2.6 — Open-Source Agentic Intelligence for Coding, Agents & Long-Context Tasks
Quick Reference
What Is Kimi K2.6?
Kimi K2.6 is an open-source large language model released by Moonshot AI, designed from the ground up for production-grade agentic workflows, software engineering, and long-context reasoning. It is the latest release in the fast-moving Kimi K2 family, a line that has consistently ranked at or near the top of the open-model leaderboard since the original K2 launched.
Unlike conventional chat models optimized for single-turn Q&A, Kimi K2.6 is purpose-built for tasks that unfold over time: refactoring a large codebase, running a 12-hour autonomous engineering workflow, or coordinating a swarm of 300 specialized sub-agents on a complex research project.
It uses a Mixture-of-Experts (MoE) architecture, which means it can route different parts of a problem to specialized parameter groups rather than activating the entire model for every token. This makes it computationally efficient without sacrificing capability — a practical advantage for developers paying per token.
The model supports a 262,144-token context window, handles image and video inputs natively via MoonViT-3D, and is available on AI/ML API with OpenAI-compatible endpoints.
Key Features of Kimi K2.6
Six defining capabilities that separate Kimi K2.6 from other open-source models currently available through the API.
262K Token Context Window
Process entire codebases, lengthy legal documents, multi-chapter research papers, or long conversation histories in a single pass without fragmentation or chunking hacks.
300-Agent Swarm Orchestration
K2.6 can decompose a complex task into subtasks and route them to up to 300 parallel specialized sub-agents, synthesizing their outputs into a unified result. Three times the scale of K2.5.
Native Tool Calling & Long-Horizon Execution
Sustains autonomous execution across 4,000+ sequential tool calls and 12+ hours without losing coherence. Ideal for CI/CD pipelines, incident response, and overnight engineering runs.
State-of-the-Art Coding
80.2% on SWE-Bench Verified and 58.6% on SWE-Bench Pro. Strong across Python, Rust, Go, TypeScript, and more, including front-end generation, DevOps, and performance optimization.
Multimodal Input (Vision)
The MoonViT-3D encoder understands screenshots, diagrams, UI mockups, and visual data natively, letting you turn a Figma design or hand-drawn sketch into working HTML/CSS in one step.
Proactive 24/7 Agents
Agents that don't wait to be asked. Once deployed, K2.6-backed agents monitor systems, execute scheduled tasks, and respond to events autonomously, demonstrated in a documented 5-day continuous engineering run.
Kimi K2.6 Benchmark Results
Across agentic, coding, and reasoning benchmarks, Kimi K2.6 competes directly with closed frontier models, including GPT-5.4 (xhigh) and Claude Opus 4.6 (max effort), while remaining openly accessible.
Agentic & Tool-Use Benchmarks
Coding Benchmarks
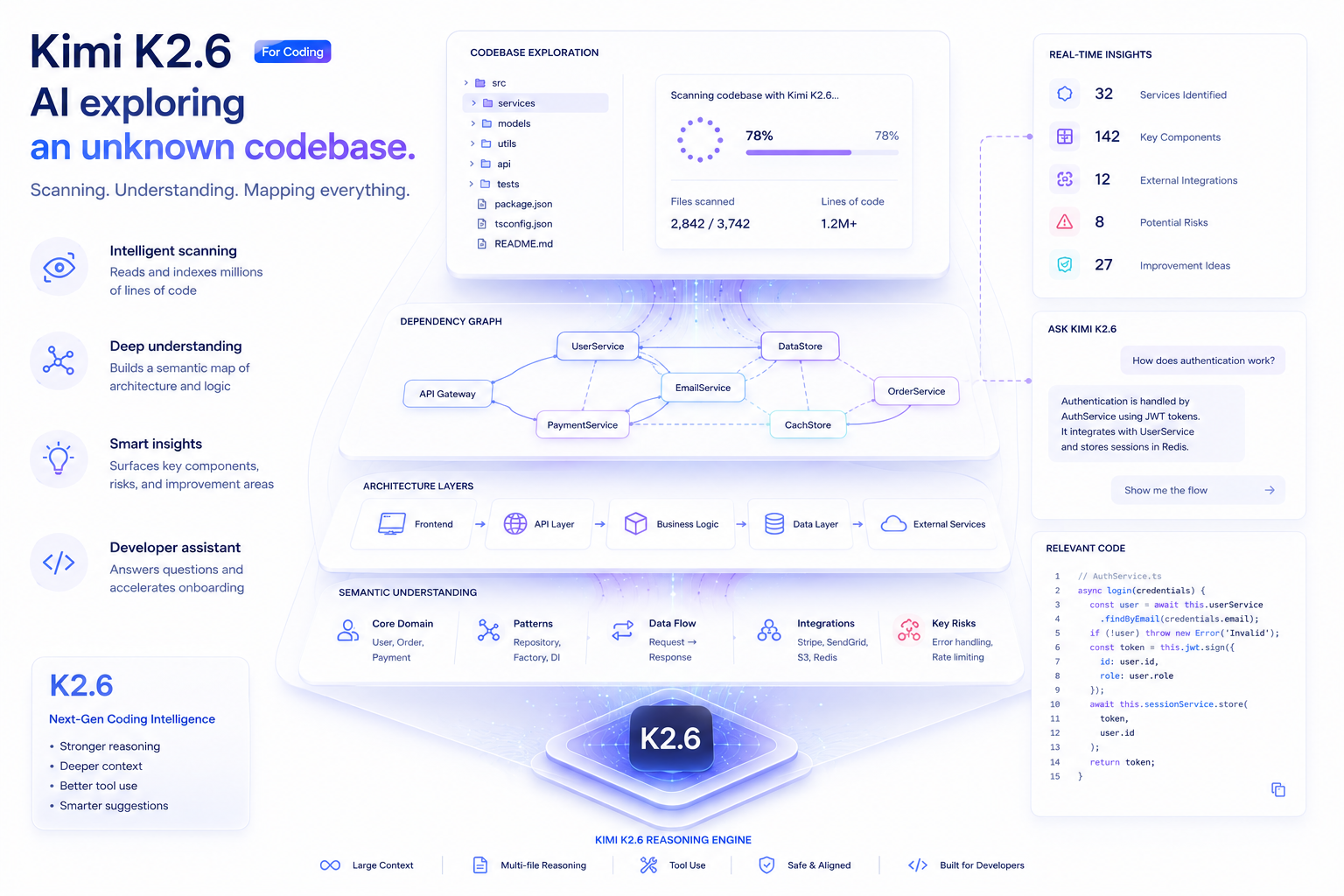
Kimi K2.6 for Coding
Coding is where K2.6 has made the most visible leap over its predecessor. It's not just that benchmark numbers moved, enterprise teams running real workloads have clocked measurable gains in task completion rates and code quality.
The model handles the full software development lifecycle without hand-holding: reading an unfamiliar codebase, writing a multi-file refactor, running the test suite, catching regressions, and iterating — all from a single high-level prompt. That said, it's most impressive when the task is genuinely long: multi-hour optimization runs, legacy codebase modernization, or multilingual full-stack projects spanning front-end, backend, and infrastructure layers.
Performance Optimization in Zig
K2.6 deployed a locally running Qwen3.5-0.8B model on macOS, then implemented and tuned model inference using Zig — a language far outside typical training data. Over 4,000+ tool calls and 12+ hours, it improved throughput:
~15 → 193 tok/s
A 20% speed improvement over LM Studio, achieved autonomously through 14 iterations.
Financial Matching Engine Overhaul
K2.6 autonomously overhauled exchange-core, an 8-year-old open-source financial matching engine, over a 13-hour execution with 1,000+ tool calls modifying 4,000+ lines of code. It analyzed CPU flame graphs, reconfigured thread topology, and extracted:
+185% throughput
From 0.43 to 1.24 MT/s medium throughput, and from 1.23 to 2.86 MT/s peak — despite the engine already being near its limits.
Full-Stack Frontend Generation
K2.6 generates complete front-end interfaces from natural language descriptions, including scroll-triggered animations, video backgrounds, and 3D effects. It extends into lightweight full-stack scenarios — handling authentication, database operations, and user interaction logic from a single prompt.
+50%
Ivement on Vercel's internal Next.js benchmark vs Kimi K2.5, putting it among the top-performing models on their platform.
Enterprise Codebase Navigation
When a fix path is blocked, K2.6 pivots intelligently — following existing architectural patterns, finding related changes across the repo, and keeping modifications scoped to the actual root cause. This reduces wasted cycles in large enterprise codebases where surgical precision matters.
96.6%
Tool invocation success rate in CodeBuddy's internal evaluation, with 12% improvement in code generation accuracy over K2.5.
What K2.6 handles well in coding workflows
Kimi K2.6 for Agents and Automation
K2.6 is purpose-built for autonomous operation, not as an afterthought, but as the primary design goal. There are three distinct modes of agentic use, each suited to different workflow scales.
Single-Agent Mode
A linear agent using tools sequentially. Best for well-scoped tasks: code review, document analysis, API integration, or debugging sessions. Reliable up to 4,000+ tool calls without context degradation.
Agent Swarm (300 Parallel Sub-Agents)
K2.6 acts as the orchestrator, decomposing a complex task into independent subtasks and dispatching them to domain-specialized agents running simultaneously. Outputs are synthesized into a unified deliverable. Used for research synthesis, competitive analysis, and multi-document generation.
Proactive 24/7 Agents
Agents that operate continuously without waiting for a user prompt. Configure them to monitor conditions, respond to events, and execute scheduled tasks. Moonshot's own RL infrastructure team ran a K2.6-backed agent for 5 days straight, handling monitoring, incident response, and system operations autonomously.
Claw Groups (Heterogeneous Agent Teams)
A research preview that lets you bring your own agents, running on any device, any model, with their own tools and memory, into a shared operational space. K2.6 coordinates the team, routes tasks by capability, and handles failure recovery automatically.
Kimi K2.6 vs Other Models
Rather than declaring a universal winner, here's where each model is genuinely stronger, so you can match the right tool to your specific workflow.
Kimi K2.6 vs Claude Opus 4.6
K2.6 leads on SWE-Bench Pro (58.6% vs 53.4%), HLE with tools (54.0% vs 53.0%), and DeepSearchQA. Claude Opus 4.6 holds a slim edge on SWE-Bench Verified (80.8% vs 80.2%). For open-source deployments, long-horizon coding, and swarm workflows, K2.6 is the stronger choice. Neither model dominates universally, it's genuine parity at the frontier.
Kimi K2.6 vs GPT-5.4
On HLE with tools (54.0% vs 52.1%) and SWE-Bench Pro, K2.6 outperforms GPT-5.4. GPT-5.4 leads on Toolathlon (54.6 vs 50.0) and benefits from a deeper tooling ecosystem. GPT-5.4 is the safer enterprise default for general tasks; K2.6 is worth the switch when open weights or large-scale agentic workflows are the priority.
Kimi K2.6 vs Kimi K2.5
K2.6 expands the swarm from 100 to 300 sub-agents and 1,500 to 4,000 coordinated steps. Enterprise partners report 12–50%+ improvements in real-world coding tasks. K2.5 remains a cost-effective option for lighter tasks, but if you're running agentic pipelines at scale, K2.6 is the clear upgrade path.
What Developers Are Using Kimi K2.6 For
K2.6 performs well across a broad set of production scenarios. Here are the use cases where it delivers the most measurable value.
Software Development
Multi-file refactors, bug hunting, performance optimization, legacy modernization, and automated testing. K2.6 handles the full dev loop without losing context across file boundaries.
Research & Analysis
Synthesizing dense scientific papers, financial reports, or competitive intelligence across dozens of sources simultaneously using Agent Swarm mode.
Workflow Automation
Deploying 24/7 proactive agents that monitor systems, handle incident response, execute scheduled operations, and adapt to new conditions — hands-free.
Frontend & UI Generation
Converting Figma mockups, screenshots, or natural language descriptions into production-ready HTML, CSS, and JavaScript with animations and responsive design included.
Long-Context Document Processing
Contract review, patent analysis, compliance checking, and multi-document summarization. The 262K context window handles entire document sets without chunking.
Enterprise Agent Pipelines
End-to-end content production, multi-market research, bulk document generation, and cross-platform data workflows, coordinated by K2.6 as the orchestrating brain.
Kimi K2.6 Pros and Cons
No model is perfect for every use case. Here's what K2.6 does well and where it has limits.
Start Building with Kimi K2.6 Today
Access 400+ AI models, including Kimi K2.6, through one unified, OpenAI-compatible API.
Frequently Asked Questions
What is Kimi K2.6?
Kimi K2.6 is an open-source, Mixture-of-Experts large language model developed by Moonshot AI. It's designed for coding, agentic workflows, long-context reasoning, and tool-based automation. It scores 80.2% on SWE-Bench Verified, supports a 262,144-token context window, and can coordinate swarms of up to 300 parallel specialized sub-agents.
Is Kimi K2.6 good for coding?
Yes, it's currently among the strongest open-source models for coding. It scores 58.6% on SWE-Bench Pro (the highest for any open model at release), 80.2% on SWE-Bench Verified, and 89.6% on LiveCodeBench v6. In real-world deployments at companies like Vercel and Augment Code, it has shown 12–50% improvements over K2.5 on production coding tasks.
Does Kimi K2.6 support long context?
Yes. Kimi K2.6 has a context window of 262,144 tokens (roughly 200,000 words). This is large enough to fit entire codebases, full legal contracts, or long research documents in a single call. For context requiring more than 1 million tokens, Gemini 3.1 Pro's long-context tier may be more appropriate.
How does Kimi K2.6 compare to Claude Opus 4.6?
They're close across most benchmarks. K2.6 leads on SWE-Bench Pro (58.6% vs 53.4%), HLE with tools (54.0% vs 53.0%), and DeepSearchQA F1 score (92.5% vs 91.3%). Claude Opus 4.6 holds a slim edge on SWE-Bench Verified (80.8% vs 80.2%) and Claw Eval. The practical difference: K2.6 is open-source and offers native 300-agent swarm orchestration, while Claude Opus 4.6 is closed-source with strong single-agent reasoning.
What is the difference between Agent Mode and Agent Swarm?
Agent Mode is a single sequential agent that uses tools one after another. It works well for focused, well-scoped tasks. Agent Swarm coordinates up to 300 specialized sub-agents running in parallel, where K2.6 acts as the orchestrator — decomposing tasks, routing to appropriate agents, and synthesizing outputs. On wide-coverage benchmarks like BrowseComp, swarm mode lifts scores from ~74.9% (K2.5 single agent) to 86.3% (K2.6 swarm).



