
1M
13
65
Chat
Inactive
Claude Mythos
Claude Mythos Preview is Anthropic's most advanced AI model to date.


Anthropic's most ambitious model yet, blending mythic-scale reasoning with practical precision.
Where most model names communicate tier (Haiku, Sonnet, Opus) or generation, Mythos points toward a different category altogether — a model intended to explore capability ceilings, not simply refine existing ones.
Claude Mythos was designed to push the limits of software engineering — to build an AI that could work through vast, complex codebases with minimal guidance. What Anthropic discovered was that those same coding and reasoning improvements produced, as a side effect, cybersecurity capabilities that exceed anything previously seen in a commercial AI model.
Claude Mythos is not an incremental upgrade to Opus. It represents a new capability tier entirely — one that Anthropic has described as "substantially beyond" every model they have previously trained. The gap on agentic coding benchmarks alone is large enough to constitute a qualitative jump, not a marginal improvement.
Mythos is designed to pursue long chains of logic without losing thread, particularly useful in legal analysis, mathematical proofs, and complex code architectures where earlier models could drift or contradict themselves partway through.
The model is tailored for trusted organizations working at research frontiers, where the task isn't just finding answers, but critically evaluating conflicting evidence across disciplines and producing defensible conclusions.
Maintaining accuracy and relevance across very large input windows has been a known weakness in prior models. Mythos Preview targets this gap specifically, keeping reasoning grounded even when working with lengthy documents, codebases, or research bodies.
Given its restricted access and Anthropic's safety-first framing, Mythos is also expected to demonstrate particularly strong alignment properties, handling sensitive domains with the kind of calibrated judgment that has historically been difficult to achieve at high capability levels.
Frontier models increasingly serve as autonomous agents rather than simple query-response tools. Mythos is built with that architecture in mind, performing multi-turn, multi-tool tasks over extended time horizons without constant human guidance.
Claude Mythos Preview sets new records across coding, mathematics, reasoning, and cybersecurity. The gaps below show Mythos versus Claude Opus 4.6, its immediate predecessor.
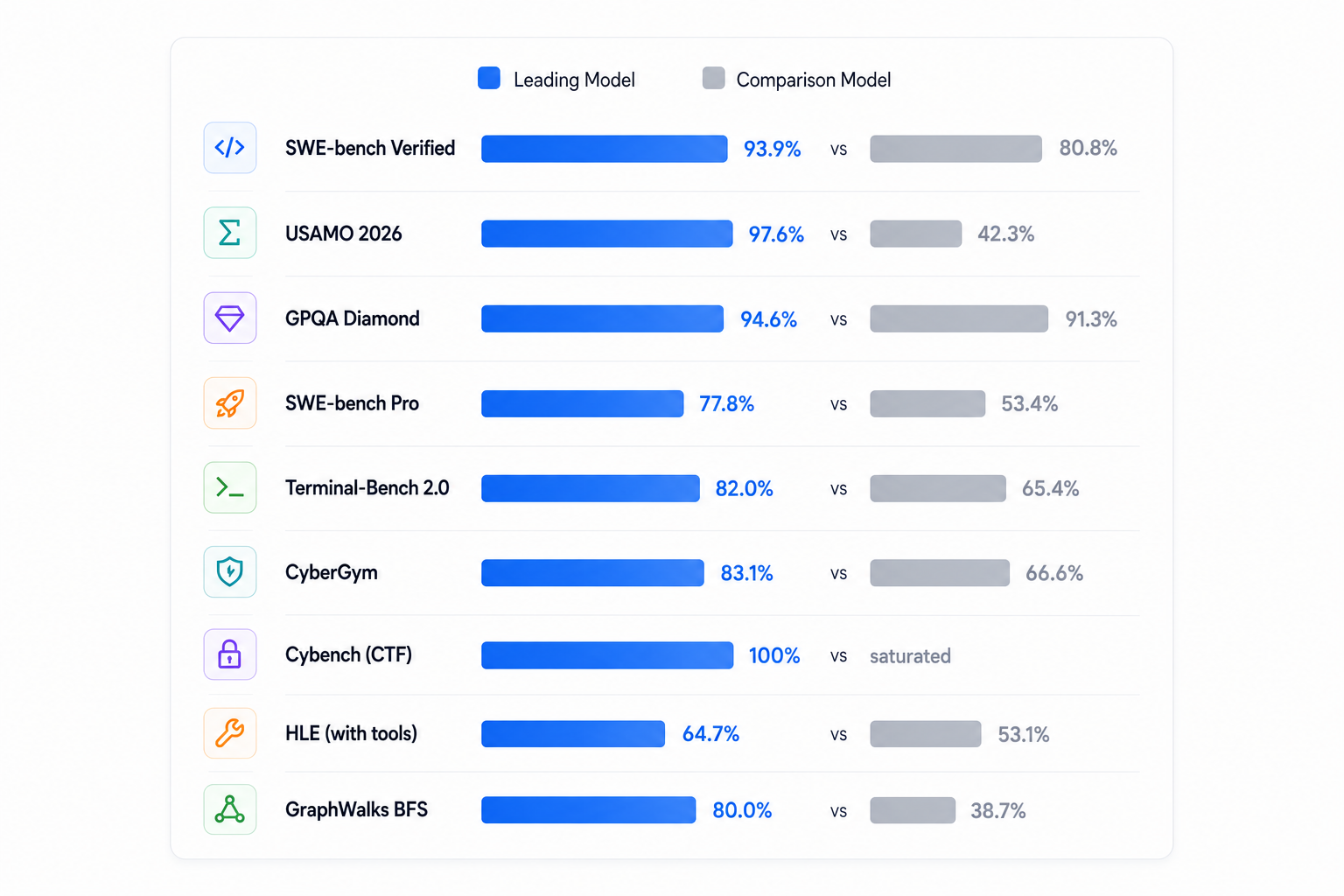
Where Mythos most visibly separates from the field and why Anthropic chose to restrict its release rather than ship it openly.
Understanding Mythos Preview requires understanding how Anthropic structures its model lineup. Claude comes in three public tiers — Haiku (fast, lightweight), Sonnet (balanced), and Opus (powerful, more deliberate). Mythos Preview sits outside this structure entirely.
Where most model names communicate tier (Haiku, Sonnet, Opus) or generation, Mythos points toward a different category altogether — a model intended to explore capability ceilings, not simply refine existing ones.
Claude Mythos was designed to push the limits of software engineering — to build an AI that could work through vast, complex codebases with minimal guidance. What Anthropic discovered was that those same coding and reasoning improvements produced, as a side effect, cybersecurity capabilities that exceed anything previously seen in a commercial AI model.
Claude Mythos is not an incremental upgrade to Opus. It represents a new capability tier entirely — one that Anthropic has described as "substantially beyond" every model they have previously trained. The gap on agentic coding benchmarks alone is large enough to constitute a qualitative jump, not a marginal improvement.
Mythos is designed to pursue long chains of logic without losing thread, particularly useful in legal analysis, mathematical proofs, and complex code architectures where earlier models could drift or contradict themselves partway through.
The model is tailored for trusted organizations working at research frontiers, where the task isn't just finding answers, but critically evaluating conflicting evidence across disciplines and producing defensible conclusions.
Maintaining accuracy and relevance across very large input windows has been a known weakness in prior models. Mythos Preview targets this gap specifically, keeping reasoning grounded even when working with lengthy documents, codebases, or research bodies.
Given its restricted access and Anthropic's safety-first framing, Mythos is also expected to demonstrate particularly strong alignment properties, handling sensitive domains with the kind of calibrated judgment that has historically been difficult to achieve at high capability levels.
Frontier models increasingly serve as autonomous agents rather than simple query-response tools. Mythos is built with that architecture in mind, performing multi-turn, multi-tool tasks over extended time horizons without constant human guidance.
Claude Mythos Preview sets new records across coding, mathematics, reasoning, and cybersecurity. The gaps below show Mythos versus Claude Opus 4.6, its immediate predecessor.
Where Mythos most visibly separates from the field and why Anthropic chose to restrict its release rather than ship it openly.
Understanding Mythos Preview requires understanding how Anthropic structures its model lineup. Claude comes in three public tiers — Haiku (fast, lightweight), Sonnet (balanced), and Opus (powerful, more deliberate). Mythos Preview sits outside this structure entirely.




.webp)



