
1M
3.25
23.4
Chat
Active
Gemini 3.5 Flash
Gemini 3.5 Flash brings near-Pro reasoning at Flash speed. Explore specs, pricing, thinking levels.


Gemini 3.5 Flash model narrows the gap between Flash-tier speed and Pro-level reasoning.
With Gemini 3.5 Flash API, Google introduces a new generation of multimodal AI designed for real-world production workloads, high-speed automation, advanced coding assistance, and scalable agentic workflows. Whether you're building AI-powered SaaS tools, enterprise copilots, customer support systems, automation pipelines, or next-generation coding agents, Gemini 3.5 Flash delivers the performance modern applications demand.
Unlike traditional heavyweight models that often sacrifice latency for reasoning quality, Gemini 3.5 Flash focuses on delivering advanced reasoning, coding capability, and multimodal understanding at Flash-level speed.
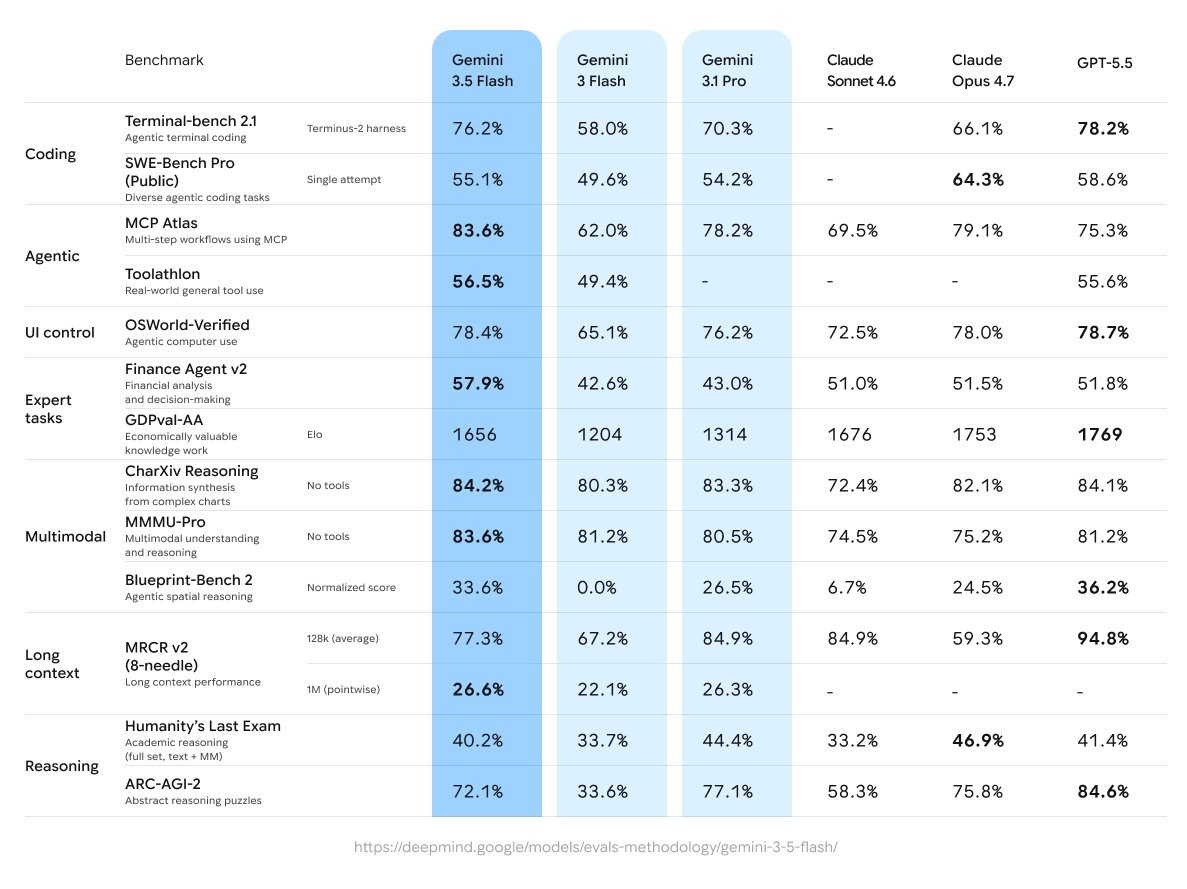
Everything developers are expecting based on current leaks, official Gemini 3 series documentation, and early tester reports.
Expected to come significantly closer to Gemini 3.1 Pro's reasoning quality while remaining faster and cheaper. Early testers report that the long-standing "lazy model" problem has been largely addressed.
Carries forward the full 1M token input context window from the Gemini 3 generation — large enough to fit entire codebases, lengthy documents, and complex multi-turn agentic conversations in a single call.
Like Gemini 3 Flash before it, 3.5 Flash is expected to support four thinking levels — minimal, low, medium, and high — letting developers trade off reasoning depth against latency and cost per request.
Accepts text, images, audio, video, and PDFs as input. Carries forward the improved audio grounding from the Gemini 3 series, including better handling of accented speech and background noise.
Leaked details point to improved search grounding reliability — a consistent pain point in earlier Gemini Flash models. If accurate, this could make 3.5 Flash significantly more useful for real-world research and factual tasks.
< 200K tokens
> 200K tokens
The thinking_level parameter lets you dial reasoning depth per request — critical for high-volume workloads where you don't want to pay Pro prices for simple tasks.
Based on everything we know so far, here's where 3.5 Flash will shine over the existing lineup.
Multi-step agent loops have historically been a weak point for Flash models — they'd drop context, hallucinate tool parameters, or give superficial answers mid-chain. 3.5 Flash is expected to handle these with the reliability previously reserved for Pro, at a fraction of the cost and latency.
Near-Pro reasoning means 3.5 Flash should handle real-world debugging, code review, and refactoring tasks that currently require reaching for Pro. The January 2026 knowledge cutoff also means better awareness of recent frameworks, package versions, and breaking API changes.
If the grounding improvements hold up at GA, 3.5 Flash should be significantly more reliable for applications where hallucination is costly — customer-facing research tools, fact-checking pipelines, and RAG systems that need accurate snippet ranking alongside low latency.
The 1M token context and expected reasoning improvements make it a strong fit for document Q&A products, legal contract analysis, and financial report parsing — tasks where Flash's speed matters but where previous Flash models sometimes gave shallow answers on dense material.
Gemini 3.5 Flash inherits the full multimodal stack, including improved audio input quality over the 2.5 generation. For applications ingesting meeting recordings, product photos, or mixed-media documents, it provides a single model rather than separate specialized endpoints.
With Gemini 3.5 Flash API, Google introduces a new generation of multimodal AI designed for real-world production workloads, high-speed automation, advanced coding assistance, and scalable agentic workflows. Whether you're building AI-powered SaaS tools, enterprise copilots, customer support systems, automation pipelines, or next-generation coding agents, Gemini 3.5 Flash delivers the performance modern applications demand.
Unlike traditional heavyweight models that often sacrifice latency for reasoning quality, Gemini 3.5 Flash focuses on delivering advanced reasoning, coding capability, and multimodal understanding at Flash-level speed.
Everything developers are expecting based on current leaks, official Gemini 3 series documentation, and early tester reports.
Expected to come significantly closer to Gemini 3.1 Pro's reasoning quality while remaining faster and cheaper. Early testers report that the long-standing "lazy model" problem has been largely addressed.
Carries forward the full 1M token input context window from the Gemini 3 generation — large enough to fit entire codebases, lengthy documents, and complex multi-turn agentic conversations in a single call.
Like Gemini 3 Flash before it, 3.5 Flash is expected to support four thinking levels — minimal, low, medium, and high — letting developers trade off reasoning depth against latency and cost per request.
Accepts text, images, audio, video, and PDFs as input. Carries forward the improved audio grounding from the Gemini 3 series, including better handling of accented speech and background noise.
Leaked details point to improved search grounding reliability — a consistent pain point in earlier Gemini Flash models. If accurate, this could make 3.5 Flash significantly more useful for real-world research and factual tasks.
< 200K tokens
> 200K tokens
The thinking_level parameter lets you dial reasoning depth per request — critical for high-volume workloads where you don't want to pay Pro prices for simple tasks.
Based on everything we know so far, here's where 3.5 Flash will shine over the existing lineup.
Multi-step agent loops have historically been a weak point for Flash models — they'd drop context, hallucinate tool parameters, or give superficial answers mid-chain. 3.5 Flash is expected to handle these with the reliability previously reserved for Pro, at a fraction of the cost and latency.
Near-Pro reasoning means 3.5 Flash should handle real-world debugging, code review, and refactoring tasks that currently require reaching for Pro. The January 2026 knowledge cutoff also means better awareness of recent frameworks, package versions, and breaking API changes.
If the grounding improvements hold up at GA, 3.5 Flash should be significantly more reliable for applications where hallucination is costly — customer-facing research tools, fact-checking pipelines, and RAG systems that need accurate snippet ranking alongside low latency.
The 1M token context and expected reasoning improvements make it a strong fit for document Q&A products, legal contract analysis, and financial report parsing — tasks where Flash's speed matters but where previous Flash models sometimes gave shallow answers on dense material.
Gemini 3.5 Flash inherits the full multimodal stack, including improved audio input quality over the 2.5 generation. For applications ingesting meeting recordings, product photos, or mixed-media documents, it provides a single model rather than separate specialized endpoints.


.jpg)

.avif)


