By delivering nearly flagship-level performance with significantly reduced active parameter counts and memory requirements, it enables organizations to deploy advanced large language model functionalities without the need for extensive computing infrastructure.
GLM-4.5-Air excels at the intersection of hardware cost-efficiency and high-quality, long-context reasoning capabilities, positioning itself as a highly practical and versatile solution for demanding real-world applications.
GLM-4.5 Air Description
Zhipu AI’s GLM-4.5-Air is a highly efficient, cost-effective large language model built with 106 billion total parameters (12 billion active) using a Mixture-of-Experts (MoE) design. Tailored for a broad spectrum of text-to-text applications, it matches the full GLM-4.5’s 128,000-token context window, enabling comprehension and generation of very long-form text while dramatically reducing computational overhead.
Technical Specification
Performance Benchmarks
Context Window: 128,000 tokens
Ranked 6th overall on 12 industry benchmarks, with a 59.8 average score
Reasoning: MMLU-Pro 81.4%, AIME24 89.4%, Math 98.1%; solid coding
Performance Metrics
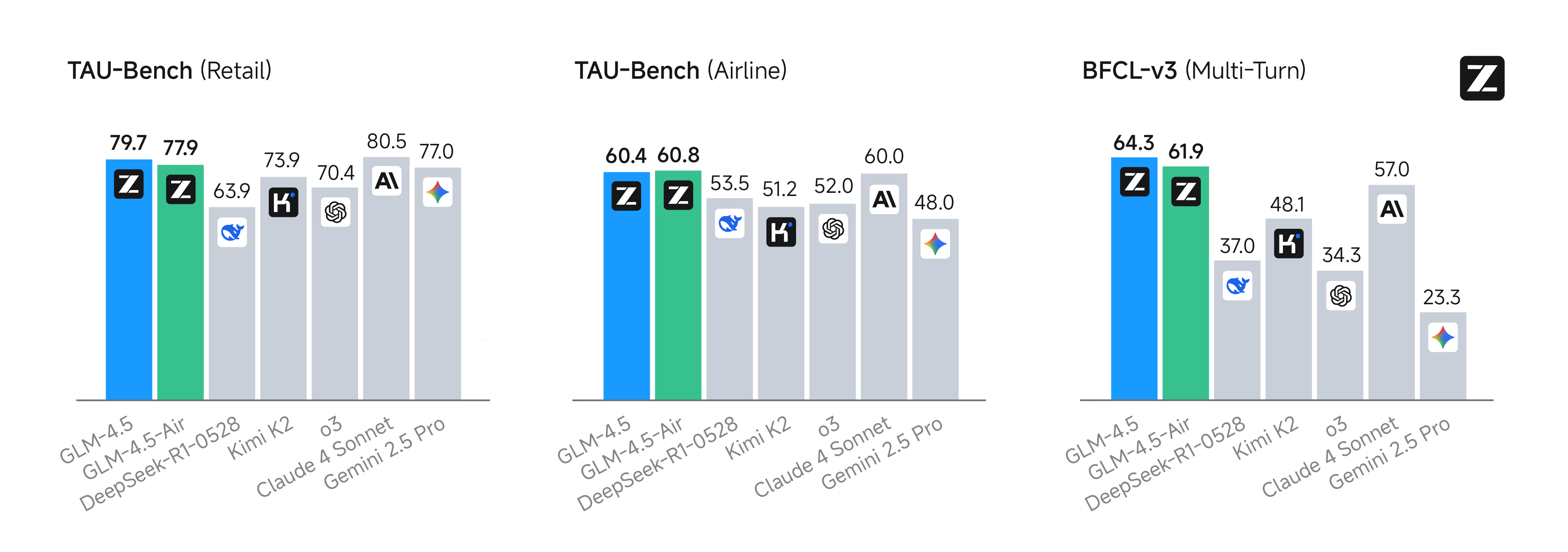
GLM-4.5-Air is engineered for agentic applications, offering a 128,000-token context window and built-in function execution capabilities. On agentic benchmarks such as τ-bench and BFCL-v3, it attains results nearly equivalent to Claude 4 Sonnet. In specialized tests for web browsing (BrowseComp), which assess complex multi-step reasoning and tool use, GLM-4.5-Air achieves a 26.4% accuracy rate, outperforming Claude-4-Opus (18.8%) and approaching the leading o4-mini-high at 28.3%. These results underscore GLM-4.5-Air’s balanced performance in real-world, tool-driven tasks and agent scenarios.
Key Capabilities
Advanced Text Generation: Fluent, contextually precise outputs for long-form and multi-turn dialogue.
Efficient Agentic Reasoning: Maintains strong coding, reasoning, and tool-use ability in both “thinking” (complex) and “non-thinking” (instant response) modes.
Resource Efficiency: Requires far less GPU memory (deployable on 16GB GPUs), making it excellent for real-world, hardware-constrained environments.
Competitive on practical development and agent tasks, with rapid code suggestion and document analysis.
API Pricing
Input: $0,63
Output: $2,31
Optimal Use Cases
Cost-Effective Conversational AI: Supports high-volume, low-latency chatbots and virtual assistants.
Lightweight Coding Assistance: Real-time code completion, debugging, and documentation generation.
Complex Document Analysis: Legal, scientific, and business text at scale.
Mobile & Edge Deployments: Effective for environments with limited hardware resources.
Agentic Tools: Tool-using agents, web browsing, and batch content transformation.
Code Sample
Comparison with Other Models
Vs. Claude 4 Sonnet: GLM-4.5-Air offers a competitive balance of efficiency and performance but is slightly behind Claude 4 Sonnet in coding and agentic reasoning tasks. Claude 4 Sonnet supports a larger context window (200k tokens vs. 128k) and includes image input capabilities, making it more suitable for multimodal applications. However, GLM-4.5-Air is open-source, more cost-effective, and provides strong reliability across function calling and multi-turn reasoning.
Vs. GLM-4.5: GLM-4.5-Air achieves about 80-98% of the flagship GLM-4.5’s performance, with significantly fewer active parameters (12B vs. 32B) and reduced resource requirements. While it slightly trails in raw task accuracy, it maintains solid reasoning, coding, and agentic capabilities, making it better suited for deployment in hardware-constrained environments.
Vs. Qwen3-Coder: GLM-4.5-Air competes well with Qwen3-Coder in coding and tool use, delivering fast and accurate code generation for complex programming tasks. GLM-4.5-Air demonstrates dominant success rates and reliable tool calling mechanisms over Qwen3-Coder.
Vs. Gemini 2.5 Pro: GLM-4.5-Air holds close on practical reasoning and coding benchmarks against Gemini 2.5 Pro. While Gemini may excel slightly in some coding and reasoning tests, GLM-4.5-Air offers a favorable balance of large context window and agentic tooling optimized for efficient real-world deployments.
Limitations
Slightly reduced overall performance and number of active parameters compared to GLM-4.5 flagship
Some complex tasks show minor drops, but core text and code abilities remain robust
Not ideal for organizations needing absolute state-of-the-art accuracy above all else
“Full” context and tool-support requires new infrastructure for best efficiency
API Integration
Accessible via AI/ML API. Documentation: available here.






.webp)