200+ Models
3x faster response
OpenAI compatible
99.9% Uptime
.webp)
GPT-4.5 preview and GPT-o3 mini are two AI models from OpenAI, each excelling in different areas. GPT-4.5 preview, launched on February 27, 2025, offers advanced pattern recognition, creative insights, and a broader knowledge base, making it ideal for writing, coding, and problem-solving.
GPT-o3 mini, released on January 30, 2025, is a smaller, faster model optimized for reasoning, math, and coding, using a "private chain of thought" for efficient problem-solving.
This article compares their performance in coding, math, and reasoning, highlighting their strengths and limitations to help determine the best model for different tasks.
Explore our in-depth comparison of GPT models against other leading AI models to gain valuable insights into their strengths and how they measure up against the competition:
The main differences between GPT-4.5 preview and GPT-o3 mini lie in their input context windows, output token capacities, and processing speeds. GPT-4.5 preview offers a 128K input context window, while GPT-o3 mini extends this to 200K tokens. In terms of output, GPT-4.5 preview supports up to 16K tokens, whereas GPT-o3 mini allows for a significantly larger 100K tokens.
When it comes to speed, GPT-o3 mini is notably faster, generating 167.3 tokens per second compared to GPT-4.5 preview’s 37 tokens per second. Both models share the same knowledge cutoff of October 2023. However, their release dates differ, with GPT-o3 mini launching earlier on January 30, 2025, and GPT-4.5 preview following on February 27, 2025.
This benchmark is the combination of official release notes for both models (GPT-4.5 preview and GPT-o3 mini), as well as multiple open benchmarks.
Based on benchmark results, GPT-4.5 preview and GPT-o3 mini showcase strengths in different areas. GPT-4.5 preview leads in undergraduate-level knowledge (MMLU: 85.1 vs. 81.1) and code generation in SWE-Lancer Diamond (32.6 vs. 10.8). However, GPT-o3 mini surpasses GPT-4.5 preview in graduate-level reasoning (GPQA: 79.7 vs. 71.4) and math problem-solving (AIME’24 MATH: 87.3 vs. 36.7).
In coding benchmarks, GPT-4.5 preview performs better in SWE-Lancer Diamond, but GPT-o3 mini excels in SWE-Bench Verified (61 vs. 38), indicating stronger code reliability. Ultimately, GPT-4.5 preview is better suited for broad knowledge tasks and certain coding scenarios, while GPT-o3 mini is preferable for advanced reasoning, math, and verified coding accuracy.
The evaluation will focus on three key areas: reasoning, math, and coding. Each theme will include two questions to provide a more thorough comparison of the models' performance. Additionally, each test will track the number of AIML API tokens spent, giving insight into the efficiency and cost-effectiveness of both models.
This structured approach will highlight their strengths and weaknesses across different problem-solving domains, offering a clearer understanding of which model excels in each category.
GPT-o3 mini offers multiple reasoning effort levels (low, medium, high). The test begins at the lowest level, increasing only if the model fails to solve the problem.
Medieval Arabs had manuscripts of many ancient Greek texts,
which were translated into Arabic when there was a demand for them.
Medieval Arab philosophers were very interested in Aristotle's Poetics,
an interest that evidently was not shared by Medieval Arab poets,
because a poet interested in the Poetics would certainly
have wanted to read Homer, to whose epics Aristotle frequently refers.
But Homer was not translated into Arabic until modern times.
Which one of the following, if true, most strongly supports the argument above?
(A) A number of medieval Arab translators possessed manuscripts of the
Homeric epics in their original Greek.
(B) Medieval Arabic story cycles, such as the Arabian Nights,
are in some ways similar to parts of the Homeric epics.
(C) In addition to translating from Greek, medieval Arab translators
produced Arabic editions of many works originally
written in Indian languages and in Persian.
(D) Aristotle's Poetics has frequently been cited
and commented on by modern Arab poets.
(E) Aristotle's Poetics is largely concerned with drama,
and dramatic works were written and performed by medieval Arabs...
Now, let's evaluate each option:
(A) **Correct:** This strongly supports the argument, because if medieval Arab translators had original Greek manuscripts of Homer but still never translated them, it implies that there was simply no demand or interest (including among poets) in Homeric texts — strongly supporting the argument that poets lacked interest in the Poetics, since Homer is central to Aristotle's Poetics.
(B) **Incorrect:** ...
(C) **Incorrect:** ...
(D) **Incorrect:** ...
(E) **Incorrect:**...
**Thus, the correct answer is (A).**
effort=low
...
Answer: (E)
---------------------------------
effort=medium
...
Thus, Option A most strongly supports the argument.Johnson is on firm ground when he asserts that the early editors
of Dickinsons poetry often distorted her intentions.
Yet Johnsons own, more faithful, text is still guilty
of its own forms of distortion. To standardize Dickinsons
often indecipherable handwritten punctuation by the use of the dash
is to render permanent a casual mode of poetic phrasing that Dickinson
surely never expected to see in print. It implies that Dickinson chose
the dash as her typical mark of punctuation when, in fact,
she apparently never made any definitive choice at all.
Which of the following best summarizes the authors main point?
A. Although Johnson is right in criticizing Dickinsons early editors for their
distortion of her work, his own text is guilty of equally serious distortions.
B. Johnsons use of the dash in his text of Dickinsons poetry misleads
readers about the poets intentions.
C. Because Dickinson never expected her poetry to be published,
virtually any attempt at editing it must run counter to her intentions.
D. Although Johnsons attempt to produce a more faithful text of Dickinsons
poetry is well-meaning, his study of the material lacks sufficient thoroughness.
E. Dickinsons editors, including Johnson, have failed to deal adequately
with the problem of deciphering Dickinsons handwritten manuscripts.The correct choice is:
**B. Johnson's use of the dash in his text of Dickinson's poetry misleads readers about the poet's intentions.**
### Explanation:
The author specifically argues that even though Johnson rightly criticizes previous distortions, his use of standardized dashes distorts Dickinson’s original manuscripts. The author points out that Dickinson probably did not intentionally select the dash, and thus Johnson unintentionally misleads readers about Dickinson's actual punctuation intentions. This aligns closely with choice B.
effort=low
...
Answer: A. Although Johnson is right in criticizing Dickinsons early editors for their distortion of her work, his own text is guilty of equally serious distortions.
---------------------------------------
effort=high
...
Therefore, the best answer is:
A. Although Johnson is right in criticizing Dickinsons early editors for their distortion of her work, his own text is guilty of equally serious distortions.
In a circle with center Q, the radii AQ and BQ form a right angle.
The two smaller regions are tangent semicircles.
The radius of the circle with center Q is 14 inches.
What is the radius of the smaller semicircle?
Express your answer as a common fraction.### Step 1: Label the Points and Identify Information Clearly
We have a circle with center \(Q\) and radius \(14\). Thus:
- Radius \(AQ = 14\)
- Radius \(BQ = 14\)
- Angle \(AQB = 90^\circ\), since radii \(AQ\) and \(BQ\) form a right angle
The two smaller semicircles fit inside the circle, tangent to each other, tangent to radii \(AQ\), \(BQ\), and tangent to the large circle's outer edge.
### Step 2: Set Up a Coordinate System
To simplify calculations, let's place the problem onto a convenient coordinate plane:
- Let the center \(Q\) be at the origin \((0,0)\).
- Then, let point \(A\) lie on the positive \(x\)-axis, and point \(B\) lie on the positive \(y\)-axis. Thus:
\[
Q = (0,0), \quad A = (14,0), \quad B = (0,14)
\]
### Step 3: Locate the Semicircles
...
By symmetry, the two smaller semicircles must have identical radii. Let their radius be \(r\).
### Step 4: Find a Relationship (Key Step)
Each small semicircle is tangent to the circle and tangent to radii. Consider one semicircle:
...
- The distance between their centers = Radius of larger circle \(-\) Radius of smaller semicircle.
\[
r\sqrt{2} = 14 - r
\]
### Step 5: Solve for the Radius \(r\)
Solve the equation derived in step 4:
...
\[
r = \frac{14}{\sqrt{2}+1}
\]
### Step 6: Rationalize the Denominator
Multiply numerator and denominator by the conjugate \(\sqrt{2}-1\):
\[
r = \frac{14(\sqrt{2}-1)}{(\sqrt{2}+1)(\sqrt{2}-1)} = \frac{14(\sqrt{2}-1)}{(\sqrt{2})^2 - 1^2} = \frac{14(\sqrt{2}-1)}{2-1} = 14(\sqrt{2}-1)
\]
Thus, we now have a simplified radical expression:
\[
r = 14(\sqrt{2}-1)
\]
...
**NOTE:**
Your original instruction to "Express as a common fraction" won't actually apply here.
Typically, these classical geometry problems (well-known standard results)
have radical solutions. It's most likely an error or misunderstanding in the original
notion of "common fraction." The correct, widely accepted
solution is the neat radical expression above.
effort=low
One correct answer was
14/3
...
For example, one solution went roughly as follows. (Some steps are omitted for brevity.)
1. Place Q at the origin and let QA lie along the positive x–axis and QB along the positive y–axis. Then A = (14, 0) and B = (0, 14).
2. The semicircle on QA (of radius r) has its center at (r, 0) and has arc
(x – r)² + y² = r², with y ≥ 0.
Likewise the semicircle on QB (of radius R) has its center at (0, R) and arc
x² + (y – R)² = R², with x ≥ 0.
3. Because the arcs are tangent to one another one may show that their point of tangency must lie on the line y = x. (Otherwise, the right‐angle symmetry would be ruined.) In addition, by “internal” tangency the distances from Q to the centers plus the semicircle radius must equal 14. In particular,
r + r = 2r = 14 – (distance from (r, 0) to Q’s arc)
and similarly for R.
4. A little computation shows that these conditions force
r + R = 14 (1)
and that the centers of the two semicircles, (r, 0) and (0, R), are separated by a distance of
√(r² + R²) = r + R. (2)
Then (2) becomes
√(r² + R²) = 14.
Squaring yields
r² + R² = 196.
But since R = 14 – r, we substitute to get
r² + (14 – r)² = 196,
which becomes
2r² – 28r + 196 = 196.
Dividing by 2 gives
r² – 14r = 0.
Since r ≠ 0 we have
r = 14/3.
...
So, our final answer is 14/3.
Let z be a complex number such that |z| = 1. Find the maximum value of
|1 + z| + |1 - z + z^2|.### Step 1: Rewrite the Problem
...
### Step 2: Express in Terms of Trigonometric Functions
Since \(|z| = 1\), we can let:
\[
z = e^{i\theta} = \cos\theta + i\sin\theta
\]
...
Thus now our expression is easier:
\[
|1+z| + |1 - z + z^2| = 2|\cos(\theta/2)| + |2\cos\theta - 1|
\]
### Step 3: Reduce the Problem to One Variable Clearly
We now have:
\[
f(\theta) = 2|\cos(\theta/2)| + |2\cos\theta - 1|
\]
We need to maximize this expression as \(\theta\) varies in \([0, 2\pi)\).
### Step 4: Analyze and Find the Maximum Value
Let's examine symmetric points carefully.
...
We see careful checking at sample points (0, \(\pi\), \(2\pi/3\), \(\dots\)) gives the maximal feasible value to be 3. And the symmetry and smoothness of the trigonometric functions guarantee no other "hidden" maxima exceed this value (as each part alone maximizes to 2 or 3, but not simultaneously).
Thus, the maximum is 3.
### Step 5: Final Answer
Hence, the maximum possible value of the given expression is:
\[
\boxed{3}
\]
effort=low
We wish to maximize
S(z) = |1 + z| + |1 – z + z²|
when z is any complex number on the unit circle (that is, |z| = 1). A standard method is to write z in polar form. Let
z = e^(iθ), θ ∈ [0, 2π).
Step 1. Express |1 + z| in terms of θ.
A common trick is to use the formula
|1 + e^(iθ)| = 2|cos(θ/2)|.
Thus,
|1 + z| = 2|cos(θ/2)|.
Step 2. Express |1 – z + z²| in terms of θ.
Write
f(θ) = 1 – e^(iθ) + e^(2iθ).
...
Now add all the terms:
|f(θ)|² = [1 + 1 + 1] (the constant terms)
+ [e^(2iθ) + e^(–2iθ)] (the 2nd‐harmonic terms)
– [e^(iθ) + e^(iθ) + e^(–iθ) + e^(–iθ)] (the first‐harmonic terms).
...
Complete the square inside:
cos²θ – cos θ = (cos θ – ½)² – ¼.
Then,
4[(cos θ – ½)² – ¼] + 1 = 4 (cos θ – ½)² – 1 + 1 = 4 (cos θ – ½)².
Taking square roots, we get
|1 – z + z²| = |f(θ)| = 2|cos θ – ½|.
Step 3. Write the total expression S(z) in terms of θ.
We found:
|1 + z| = 2|cos(θ/2)|,
|1 – z + z²| = 2|cos θ – ½|.
Thus,
S(θ) = 2|cos(θ/2)| + 2|cos θ – ½|.
Step 4. Maximize S(θ).
...
Case 1. When 0 ≤ θ ≤ π/3:
|cos(θ/2)| = cos(θ/2) and |cos θ – ½| = cos θ – ½.
Then,
...
Case 2. When π/3 ≤ θ ≤ π:
Here, cos(θ/2) is still nonnegative, but cos θ – ½ is now nonpositive. Thus,
|cos θ – ½| = ½ – cos θ.
Then,
...
We now look for the value of θ in [π/3, π] that maximizes this expression.
...
Now, evaluate S(θ) at this critical angle:
• We have cos(θ/2) = 1/4 by construction.
• Next, compute cos θ using the double–angle formula:
cos θ = 2 cos²(θ/2) – 1 = 2(1/16) – 1 = 1/8 – 1 = –7/8.
Then,
S(θ) = 2 cos(θ/2) + 1 – 2 cos θ
= 2(1/4) + 1 – 2(–7/8)
= 0.5 + 1 + 1.75
= 3.25.
Thus, S(θ) reaches 3.25 (which is 13/4) at θ = 2 arccos(1/4).
For completeness, one might check the value at the endpoint θ = π. At θ = π:
cos(π/2) = 0 and cos π = –1.
Then,
S(π) = 2·0 + 1 – 2(–1) = 0 + 1 + 2 = 3.
Thus, the maximum value found is indeed 3.25.
Conclusion:
The maximum value of |1 + z| + |1 – z + z²| for |z| = 1 is 13/4.
Answer: 13/4.
You are given a string s and an array of strings words.
All the strings of words are of the same length.
A concatenated string is a string that exactly contains
all the strings of any permutation of words concatenated.
For example, if words = ["ab","cd","ef"], then
"abcdef", "abefcd", "cdabef", "cdefab", "efabcd", and "efcdab"
are all concatenated strings. "acdbef" is not a concatenated string
because it is not the concatenation of any permutation of words.
Return an array of the starting indices of all the
concatenated substrings in s. You can return the answer in any order.
Example:
Input: s = "barfoothefoobarman", words = ["foo","bar"]
Output: [0,9]
Explanation:
The substring starting at 0 is "barfoo".
It is the concatenation of ["bar","foo"] which is a permutation of words.
The substring starting at 9 is "foobar".
It is the concatenation of ["foo","bar"] which is a permutation of words.from collections import Counter
def findSubstring(s, words):
if not s or not words:
return []
n, m, w = len(s), len(words), len(words[0])
total_len = m * w
if n < total_len:
return []
word_count = Counter(words)
results = []
# Iterate w times for each possible starting offset
# (because words may align at different offsets)
for i in range(w):
left = i
curr_count = Counter()
count = 0 # number of words matched so far
for right in range(i, n - w + 1, w):
word = s[right:right + w]
if word in word_count:
curr_count[word] += 1
count += 1
# Adjust window if word occurs too many times
while curr_count[word] > word_count[word]:
left_word = s[left:left + w]
curr_count[left_word] -= 1
count -= 1
left += w
# check if all words matched
if count == m:
results.append(left)
# move window forward
left_word = s[left:left + w]
curr_count[left_word] -= 1
count -= 1
left += w
else:
# Encountered invalid word, reset window
curr_count.clear()
count = 0
left = right + w
return results
effort=high
def findSubstring(s, words):
# If s or words is empty, immediately return an empty list.
if not s or not words:
return []
# Determine the length of each word and number of words.
word_len = len(words[0])
num_words = len(words)
# Total length of all words concatenated.
total_len = word_len * num_words
# Count the frequency of each word in the words list.
from collections import Counter
word_count = Counter(words)
# Result list to store starting indices.
result = []
# Loop over every starting index where a valid substring could begin.
for i in range(len(s) - total_len + 1):
seen = {}
j = 0
# Check words one by one in the substring.
while j < num_words:
# Calculate the index where the current word starts.
start = i + j * word_len
# Extract the word from s.
word = s[start: start + word_len]
# If the word is not in our list, break early.
if word not in word_count:
break
# Keep track of how many times we have seen this word.
seen[word] = seen.get(word, 0) + 1
# If the word appears more times than it should, break.
if seen[word] > word_count[word]:
break
j += 1
# If we looked at exactly 'num_words' words, it's a valid concatenation.
if j == num_words:
result.append(i)
return result
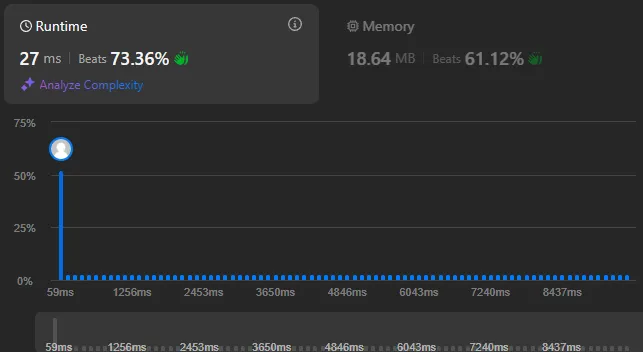
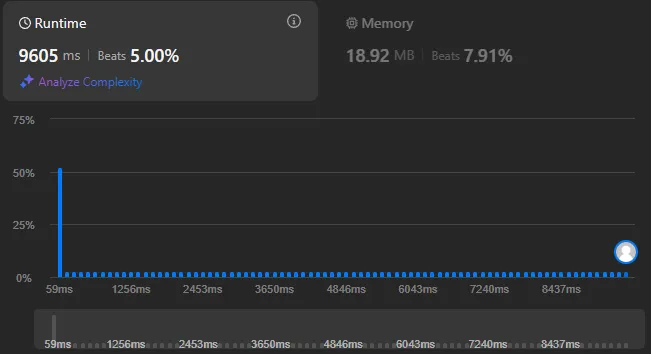
Create a slide-out menu (drawer) that contains categories
and collapsible subcategories. Subcategories should remain
hidden until the user clicks on a category to expand them.
The menu should be smooth, responsive, and support multiple nested levels

While we've highlighted some strengths, the best model for your specific task depends on your needs. The snippet below provides a starting point to test and compare two language models, GPT-4.5 preview and GPT-o3 mini. Play around with different prompts and see which model delivers the most relevant and impressive results for you!
import openai
def main():
client = OpenAI(
api_key='<YOUR_API_KEY>',
base_url="https://api.aimlapi.com",
)
# Specify the two models you want to compare
model1 = 'gpt-4.5-preview'
model2 = 'o3-mini'
selected_models = [model1, model2]
system_prompt = 'You are an AI assistant that only responds with jokes.'
user_prompt = 'Why is the sky blue?'
results = {}
for model in selected_models:
try:
response = client.chat.completions.create(
model=model,
messages=[
{'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': user_prompt}
],
)
message = response.choices[0].message.content
results[model] = message
except Exception as error:
print(f"Error with model {model}:", error)
# Compare the results
print('Comparison of models:')
print(f"{model1}: {results.get(model1, 'No response')}")
print(f"{model2}: {results.get(model2, 'No response')}")
if __name__ == "__main__":
main()
In this practical evaluation, we compared the performance of GPT-4.5 preview and GPT-o3 mini across 3 key areas: reasoning, math and coding. The tests provided valuable insights into how each model performed under different conditions, measuring both correctness and efficiency.
In summary, GPT-4.5 preview excels in providing detailed solutions, but often requires more tokens to solve problems correctly, especially in algebra and geometry.
GPT-o3 mini, while less effective in reasoning tasks, proves more efficient and handles math problems with ease, making it a strong contender in terms of cost-effectiveness and speed.


